Apple researcher Filip Granqvist walks NeurIPS 2024 attendees through the poster for “PFL research: Simulation Framework for Accelerating Research in Private Federated Learning.”
Apple researcher Filip Granqvist walks NeurIPS 2024 attendees through the poster for “PFL research: Simulation Framework for Accelerating Research in Private Federated Learning.”
Apple researchers advance AI and ML through fundamental research, and to support the broader research community and help accelerate progress in this field, we share much of this work through publications and engagement at conferences.
Next month, the 39th annual Conference on Neural Information Processing Systems (NeurIPS), will be held in San Diego, California, with a satellite event also taking place in Mexico City, Mexico. Apple is proud to once again to participate in this important event for the community and to support it with our sponsorship.
NeurIPS attendees will be able to experience demonstrations of Apple’s ML research in our booth # 1103, during exhibition hours. Apple is also sponsoring and participating in a number of affinity group-hosted events that support underrepresented groups in the ML community. A comprehensive overview of Apple’s participation in and contributions to NeurIPS 2025 can be found here, and a selection of highlights follow below.
At Apple, we believe privacy is a fundamental human right, and advancing privacy-preserving techniques in AI and ML is an important area of ongoing research. The work Apple researchers will present at NeurIPS this year includes several papers sharing progress in this area.
Accurately estimating a discrete distribution from samples is a fundamental task in statistical ML. Measuring accuracy by the Kullback-Leibler (KL) divergence error is useful for promoting diversity and smoothness in the estimated distribution, and is important in a range of contexts, including data compression, speech recognition, and language modeling. In the Spotlight paper, Instance-Optimality for Private KL Distribution Estimation, Apple researchers explore how to estimate probability distributions accurately while protecting privacy. The work focuses on instance-optimality - designing algorithms that adapt to each specific dataset and perform nearly as well as the best possible method for that case. The paper shares new algorithms that achieve this balance both with and without differential privacy, showing that distributions can be estimated accurately under KL error, while mathematically guaranteeing that no single person’s data can be inferred.
In differential privacy, randomizing which data points are used in computations can amplify privacy, making it more difficult to connect data to an individual. In the Spotlight paper, Privacy Amplification by Random Allocation, Apple researchers analyze a new sampling strategy referred to as random allocation. In this sampling scheme a user’s data is used in k steps chosen randomly and uniformly from a sequence (or set) of t steps. The paper provides first theoretical guarantees and numerical estimation algorithms for this scheme. This allows for better privacy analyses (and hence better privacy-utility tradeoffs) for a host of important algorithms such as popular variants of differentially private SGD and algorithms for efficient secure aggregation, such as those presented in PREAMBLE: Private and Efficient Aggregation via Block Sparse Vectors, another paper that Apple researchers will present at NeurIPS this year.
Reasoning is an important capability for AI, enabling systems to accomplish complex objectives that require planning and multiple steps - such as solving math and coding problems, as well as tasks for robots and virtual assistants. While the field has made significant progress in developing reasoning models, fundamental research that rigorously investigates the strengths and limitations of current approaches is essential to further advancing this capability for the future.
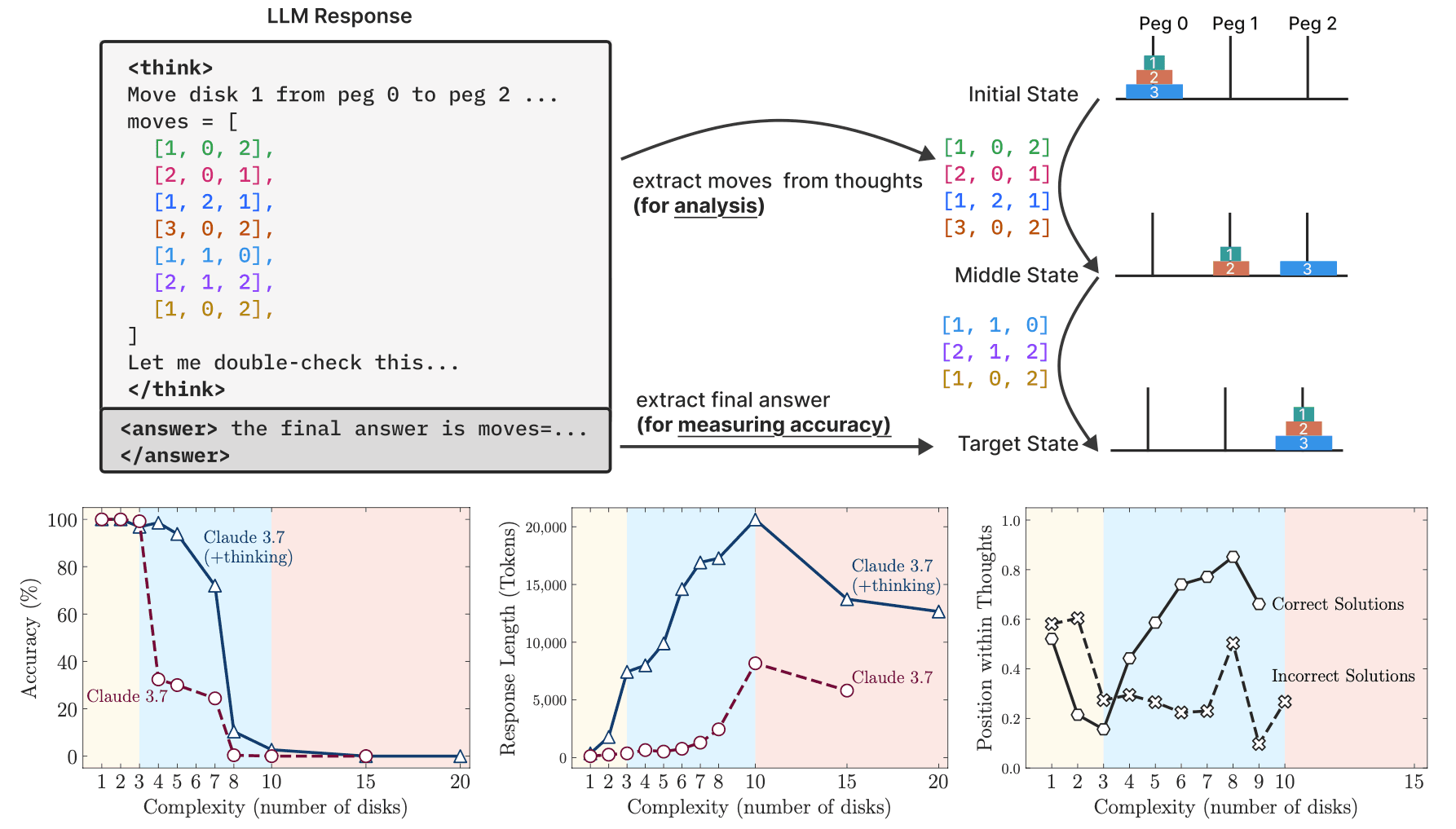
At NeurIPS, Apple researchers will present The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity, which explores how current AI models handle complex reasoning tasks. With controllable puzzle environments, the work systematically tests how these models’ performance changes as problems increase in complexity (see Figure 1). The paper shows that the accuracy of frontier Large Reasoning Models (LRMs) collapses beyond certain complexities, and finds that LRMs’ reasoning effort increases along with the complexity of a challenge - up to a point - and then it declines, despite having a sufficient token budget. The work also compares the performance of Large Reasoning Models (LRMs) and LLMs with equal inference compute, finding that LLMs outperform LRMs for low-complexity tasks, LRMs show an advantage in medium-complexity tasks, and both types fail for high-complexity tasks. The paper provides insight into LRMs’ strengths and limitations, raising crucial questions about these models’ reasoning capabilities today, which may ultimately illuminate opportunities to make LRMs more capable in the future.
One of the authors of the above paper will also deliver an Expo Talk on the topic of reasoning on Tuesday, December 2, at 8:30am PST in the Upper Level Ballroom 20AB. The talk will provide a critical review of reasoning in language models, highlight why current evaluations can be misleading, and emphasize that reasoning is not just about “what” models answer, but “how” they solve problems.
Figure 1: Our setup enables verification of both final answers and intermediate reasoning traces, allowing detailed analysis of model thinking behavior.
The industry has made impressive progress in high-resolution image generation models, but the dominant approaches also have undesirable characteristics. Diffusion models are computationally expensive in both training and inference, autoregressive generative models can be expensive at inference and require quantization that can adversely affect their output’s fidelity, and hybrid models that apply autoregressive techniques directly in continuous space are complex.
In the NeurIPS Spotlight paper, STARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis, Apple researchers share a scalable approach that generates comparable quality high-resolution images (see Figure 2), without the computational cost and complexity of prior methods. This method builds on the Transformer Autoregressive Flow (TARFlow), which combines normalizing flows (NF) and the autoregressive transformer architecture. STARFlow produces images at resolutions and quality levels previously thought unreachable for NF models, rivaling top diffusion and autoregressive methods while maintaining exact likelihood modeling and faster inference. This work is the first successful demonstration of normalizing flows at this scale and resolution, and it shows that normalizing flows are a powerful alternative to diffusion models for AI image generation.
Figure 2: generated samples from our model with variable aspect ratios.
As generative AI models become increasingly widely used, efficient methods to control their generations - for example to ensure they produce safe content or provide users with the ability to explore style changes - are becoming increasingly important. Ideally, these methods should maintain output quality, and not require a large amount of data or computational cost at training or inference time.
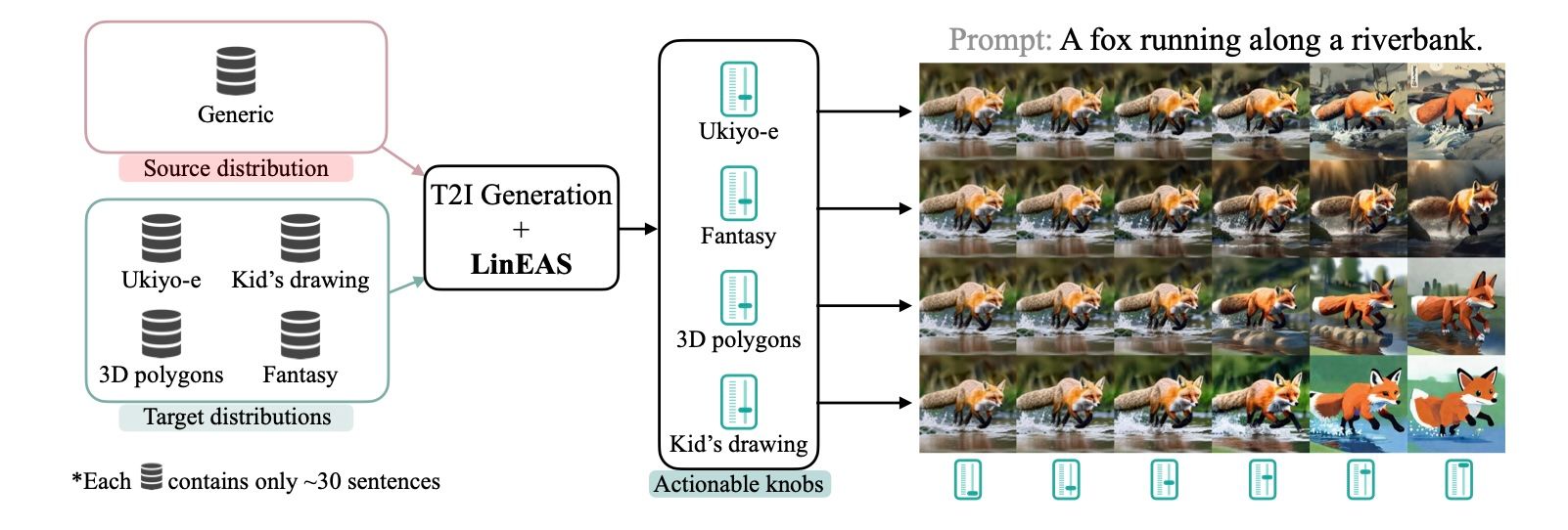
Apple researchers have previously demonstrated that an effective and efficient approach to this challenge is intervening exclusively on model activations, with the goal of correcting distributional differences between activations seen when using prompts from a source vs. a target set (e.g. toxic and non-toxic sentences). At NeurIPS, Apple researchers will present LinEAS: End-to-end Learning of Activation Steering with a Distributional Loss,which describes linear end-to-end activation steering (LinEAS), an approach trained with a global loss that accounts simultaneously for all layer-wise distributional shifts (see Figure 3). LinEAS only requires a handful of unpaired samples to be effective, and beats similar baselines on toxicity mitigation in language models. Its global optimization allows including a sparsity regularization, resulting in more precise and targeted interventions that are effective while preserving the base model fluency. This method is modality-agnostic is shown to outperform existing activation-steering methods at mitigating and including new concepts at the output of single-step text-to-image generation models.
Figure 3: LinEAS learns lightweight maps to steer pretrained model activations. With LinEAS, we gain fine-grained control on text-to-image generation to induce precise styles (in the figure) or remove objects. The same procedure also allows controlling LLMs.
Large foundation models are typically trained on data from multiple domains, and the data mixture - the proportion of each domain used in training - plays a critical role in model performance. The standard approach to selecting this mixture relies on trial and error, which becomes impractical for large-scale pretraining.
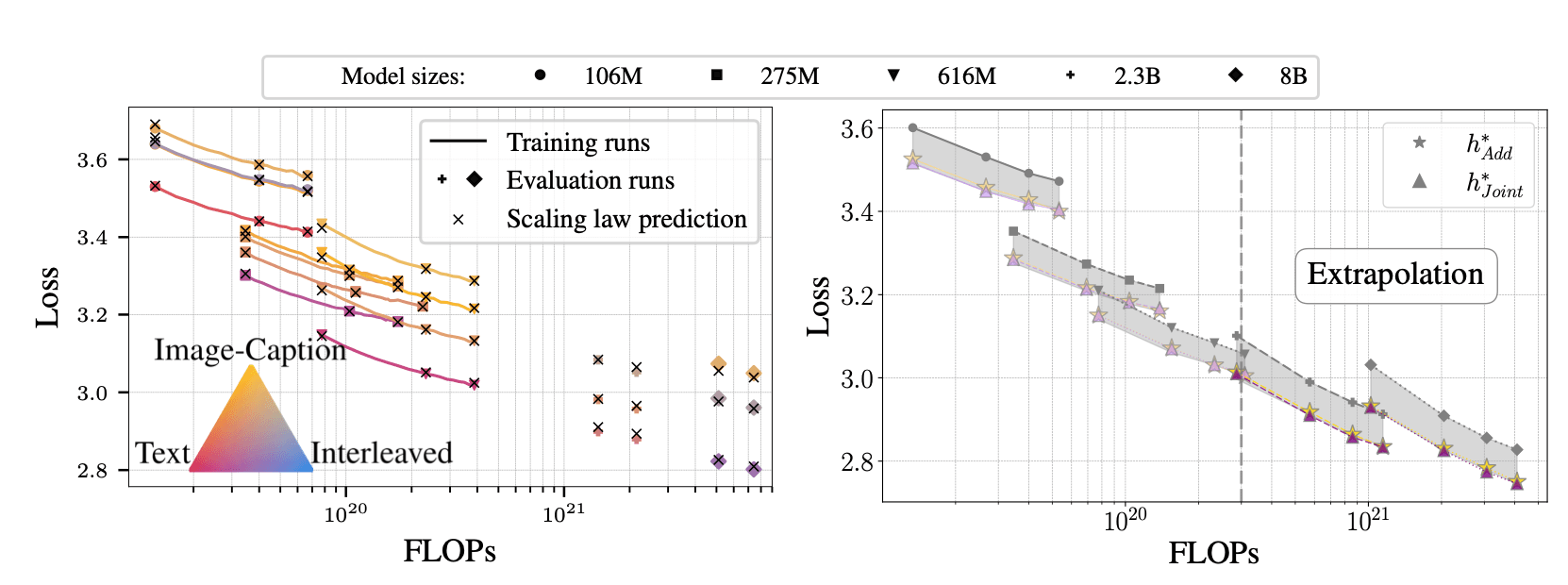
At NeurIPS, Apple researchers will present Scaling Laws for Optimal Data Mixtures, which provides a better approach to this fundamental challenge. The paper shares a systematic method to determine the optimal data mixture for any target domain using scaling laws (see Figure 4). The scaling laws predicts the loss of a model of size N trained with D tokens with a mixture h . The paper shows that these scaling laws are universal, and demonstrates their predictive power for large-scale pretraining of large language models (LLMs), native multimodal models (NMMs), and large vision models (LVMs). It also shows that these scaling laws can extrapolate to new data mixtures and across scales: their parameters can be accurately estimated using a few small-scale training runs, and used to estimate the performance at larger scales and unseen domain weights. The scaling laws allow practitioners to derive the optimal domain weights for any target domain under a given training budget (N, D), providing a principled alternative to costly trial-and-error methods.
Figure 4: Left: We derive scaling laws that predict the loss of a model as a function of model size N, number of training tokens D, and the domain weights used to train the model (represented by the color of each point). The scaling law is fitted with small-scale runs with different domain weights, and used to predict accurately the loss of large-scale models trained with new, unseen domain weights. Right: We find the data mixture scaling law based on small-scale experiments (e.g., below 1B parameters) and use it to predict the optimal data mixture at larger scales (e.g., 8B parameters). Both our additive and joint laws lead to similar performance, and better than other mixtures (in the gray area).
During exhibition hours, NeurIPS attendees will be able to interact with live demos of Apple ML research in booth # 1103. These include:
MLX - an open source array framework designed for Apple silicon that enables fast and flexible ML and scientific computing on Apple hardware. The framework is optimized for Apple silicon’s unified memory architecture and leverages both the CPU and GPU. Visitors will be able to experience two MLX demos:
Image generation with a large diffusion model on an iPad Pro with M5 chip
Distributed compute with MLX and Apple silicon: Visitors will be able to explore text and code generation with a 1 trillion-parameter model running in Xcode on a cluster of four Mac Studios equipped with M3 Ultra chips, each operating with 512 GBs of unified memory.
FastVLM - a family of mobile-friendly vision language models, built using MLX. These models use a mix of CNN and Transformer architectures for vision encoding designed specifically for processing high-resolution images. Together, they demonstrate a strong approach that achieves an optimal balance between accuracy and speed. Visitors will get to experience a real-time visual question-and-answer demo on iPhone 17 Pro Max.
Apple is committed to supporting underrepresented groups in the ML community, and we are proud to again sponsor several affinity groups hosting events onsite at NeurIPS 2025 in San Diego, including Women in Machine Learning (WiML) (workshop on December 2), LatinX in AI (workshop on December 2), and Queer in AI (workshop and evening social on December 4). In addition to supporting these workshops with sponsorship, Apple employees will also be participating at each of these, as well as other events taking place during the conference.
This post highlights just a handful of the works Apple ML researchers will present at NeurIPS 2025, and a comprehensive overview and schedule of our participation can be found here.
Apple researchers are advancing AI and ML through fundamental research, and to support the broader research community and help accelerate progress in this field, we share much of this research through publications and engagement at conferences. Next week, the International Conference on Machine Learning (ICML) will be held in Vancouver, Canada, and Apple is proud to once again participate in this important event for the…
Apple researchers are advancing the field of ML through fundamental research that improves the world’s understanding of this technology and helps to redefine what is possible with it. This work may lead to advancements in Apple’s products and services, and the benefits of the research extend beyond the Apple ecosystem as it is shared with the broader research community through publication, open source resources, and engagement at industry and…