content type paperpublished September 2025
Scaling Laws for Optimal Data Mixtures
AuthorsMustafa Shukor†, Louis Bethune, Dan Busbridge, David Grangier, Enrico Fini, Alaaeldin El-Nouby, Pierre Ablin
Scaling Laws for Optimal Data Mixtures
AuthorsMustafa Shukor†, Louis Bethune, Dan Busbridge, David Grangier, Enrico Fini, Alaaeldin El-Nouby, Pierre Ablin
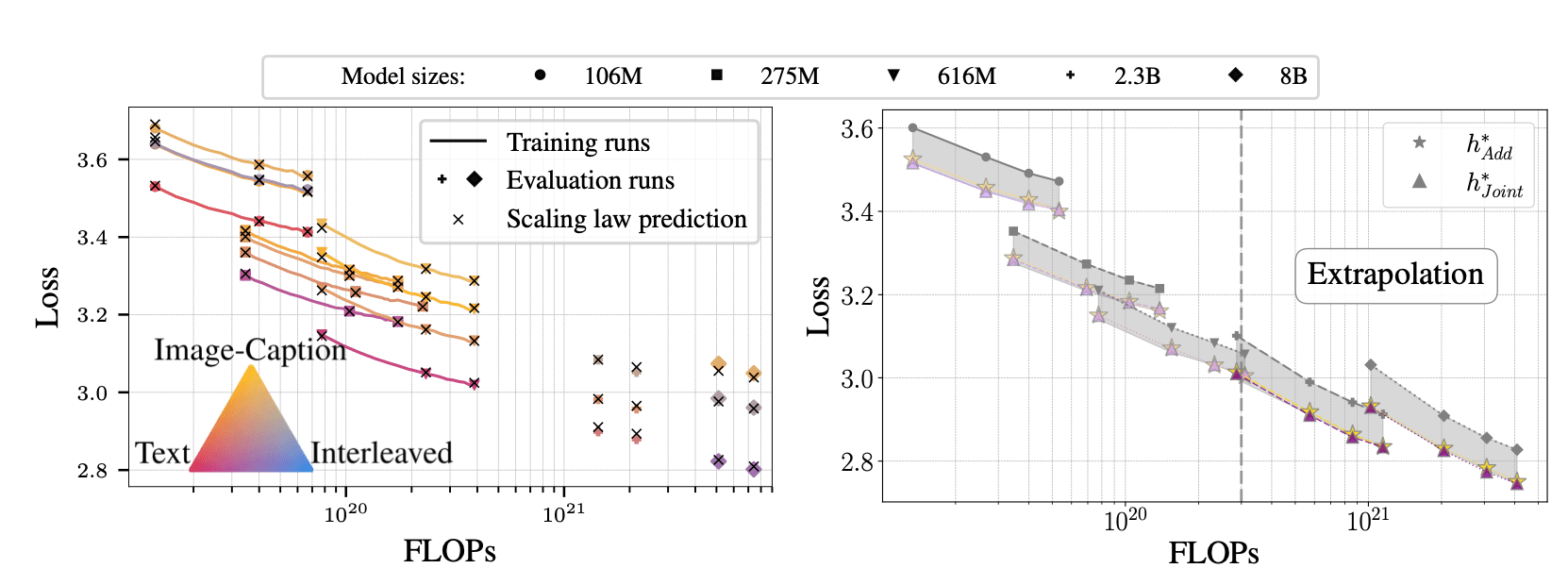
Large foundation models are typically trained on data from multiple domains, with the data mixture—the proportion of each domain used—playing a critical role in model performance. The standard approach to selecting this mixture relies on trial and error, which becomes impractical for large-scale pretraining. We propose a systematic method to determine the optimal data mixture for any target domain using scaling laws. Our approach accurately predicts the loss of a model of size N trained with D tokens and a specific domain weight vector h. We validate the universality of these scaling laws by demonstrating their predictive power in three distinct and large-scale settings: large language model (LLM), native multimodal model (NMM), and large vision models (LVM) pretraining. We further show that these scaling laws can extrapolate to new data mixtures and across scales: their parameters can be accurately estimated using a few small-scale training runs, and used to estimate the performance at larger scales and unseen domain weights. The scaling laws allow to derive the optimal domain weights for any target domain under a given training budget (N,D), providing a principled alternative to costly trial-and-error methods.
MixAtlas: Uncertainty-aware Data Mixture Optimization for Multimodal LLM Midtraining
April 16, 2026research area Computer Vision, research area Methods and AlgorithmsWorkshop at ICLR
This paper was accepted at the Workshop on Navigating and Addressing Data Problems for Foundation Models (NADPFM) at ICLR 2026.
Principled domain reweighting can substantially improve sample efficiency and downstream generalization; however, data-mixture optimization for multimodal pretraining remains underexplored. Current multimodal training recipes tune mixtures from only a single perspective such as data format or task type. We introduce…
Apple Machine Learning Research at NeurIPS 2025
November 21, 2025
Apple researchers advance AI and ML through fundamental research, and to support the broader research community and help accelerate progress in this field, we share much of this work through publications and engagement at conferences.
Next month, the 39th annual Conference on Neural Information Processing Systems (NeurIPS), will be held in San Diego, California, with a satellite event also taking place in Mexico City,…

Our research in machine learning breaks new ground every day.