content type highlightpublished June 5, 2023
Fast Class-Agnostic Salient Object Segmentation
Fast Class-Agnostic Salient Object Segmentation
In 2022, we launched a new systemwide capability that allows users to automatically and instantly lift the subject from an image or isolate the subject by removing the background. This feature is integrated across iOS, macOS, iPadOS and accessible in several apps like Photos, Preview, Safari, Keynote, and more. Underlying this feature is an on-device deep neural network that performs real-time salient object segmentation — or categorizes each pixel of an image as either a part of the foreground or background. Each pixel is assigned a score, denoting how likely it is to be part of the foreground. While prior methods often restrict this process to a fixed set of semantic categories (like people and pets), we designed our model to be unrestricted and generalize to arbitrary classes of subjects (for example, furniture, apparel, collectibles) — including ones it hasn’t encountered during training. While this is an active area of research in Computer Vision, there are many unique challenges that arise when considering this problem within the constraints of a product ready to be used by consumers. This year, we are launching Live Stickers in iOS and iPadOS, as seen in Figure 1, where static and animated sticker creation are built on the technology discussed in this article. In the following sections, we’ll explore some of these challenges and how we approached them.
An important consideration guided the design of this model: low latency. In apps like Photos, the subject lifting model is executed on user interaction (for example, touches and holds on a photo subject). To maintain a seamless user experience, the model must have extremely low latency.
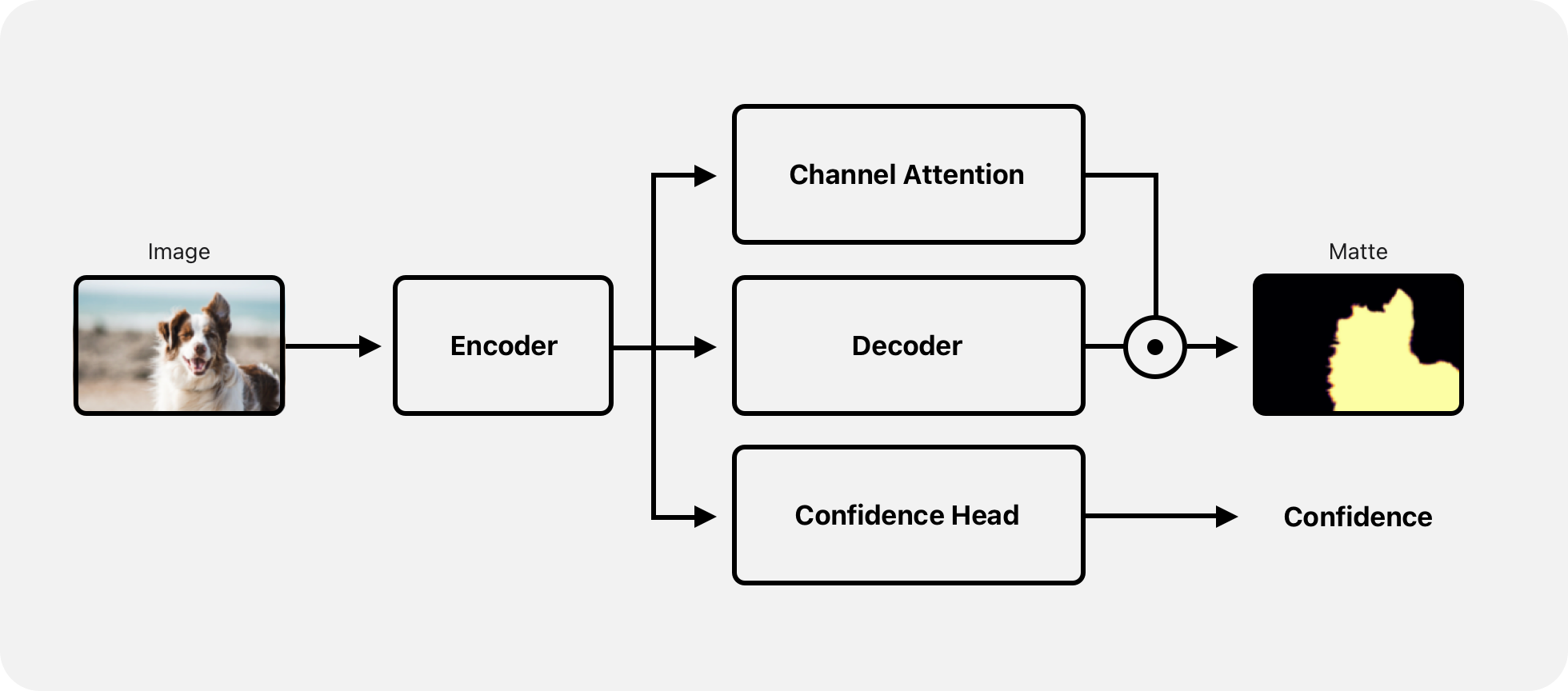
The high-level design of the model is described in Figure 2. The source image is resampled to 512×512 and fed to a convolutional encoder based on EfficientNet v2. Features extracted at varying scales are fused and upsampled using a convolutional decoder. There are two additional branches from the terminal feature of the encoder: one branch predicts an affine channel-wise reweighting for the decoded channels. This is analogous to the dynamic convolution branch described in the panoptic segmentation work in our research article, “On-device Panoptic Segmentation for Camera Using Transformers.” The other branch predicts a scalar confidence score. It estimates the likelihood of a salient foreground in the scene and can be used for gating the segmentation output. The final prediction is a single-channel alpha matte that matches the input resolution of 512×512.
On iPhone, iPad and Mac with Apple silicon, the network executes on the Apple Neural Engine. The typical execution time on an iPhone 14 is under 10 milliseconds. On older devices, the network executes on the GPU, taking advantage of Metal Performance Shaders that have been optimized for efficiency.
The components downstream from the network that produce the final matted result are also optimized for low latency. For example, the upsampling and matting operate in place to avoid copy overheads using optimized Metal kernels on the GPU.
To achieve a shipping-quality model we must solve several data-related challenges as it relates to salient object segmentation. First, there’s the class-agnostic nature of the task. In contrast to the related task of semantic segmentation, which typically restricts its outputs to a fixed set of categories, our model is designed to handle arbitrary objects. To achieve this, we resorted to a couple of strategies:
Another important consideration for the training data is minimizing bias. Toward that end, we regularly analyzed the results from our model to ensure it was fair with respect to factors such as gender and skin tone.
Confidence-based gating. The segmentation network is trained to produce high-quality alpha mattes for salient objects in the scene without being constrained to any specific semantic categories. However, the inherently ill-posed nature of this task can lead to surprising results at times. To avoid presenting such unexpected results to the user, we train a separate lightweight branch that takes the terminal encoder features as the input and outputs the likelihood of the input image containing a salient subject. Any results produced by the segmentation branch are only presented to the user if this confidence is sufficiently high.
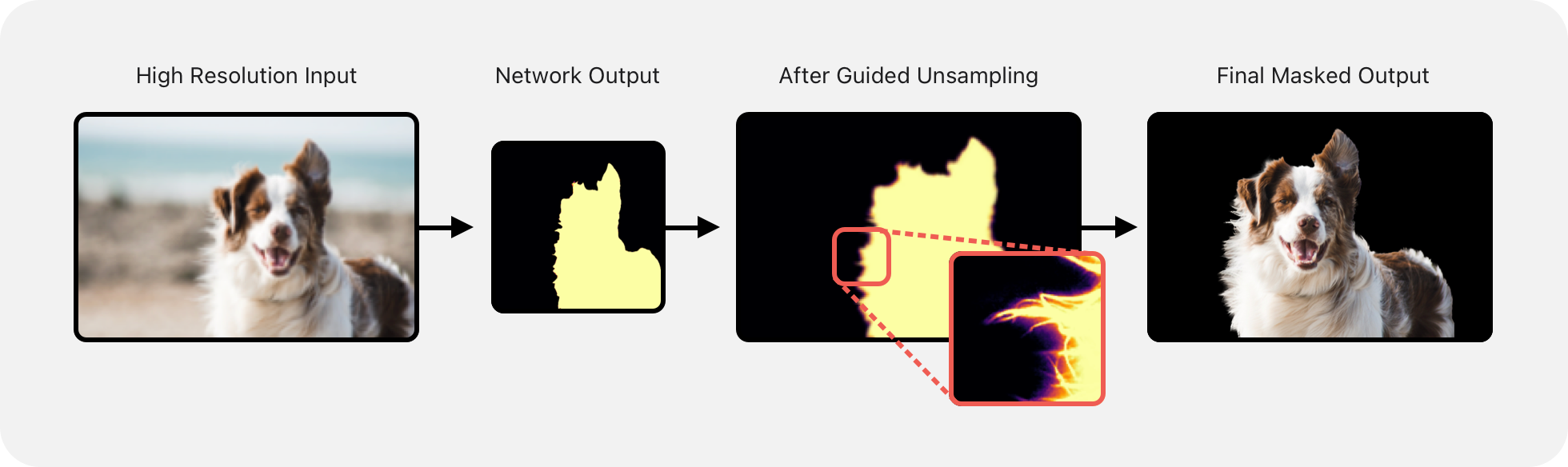
Detail preserving upsampling. For performance reasons described earlier, the segmentation mask is always predicted at a fixed resolution of 512×512. This intermediate resolution is further processed to match the source image’s resolution, which can be significantly higher (for example, a 12 MP photo captured using an iPhone has a resolution of 3024×4032). To preserve the subject’s fine-grained details, such as hair and fur, a content-aware upsampling method is used, as referenced in the paper Guided Image Filtering.
Instance lifts. The isolated foreground may include multiple distinct instances. Each separated instance can be individually selected and used for downstream tasks like mask tracking for generating animated stickers.
Evaluating model quality. During model development, we tracked metrics commonly used in salient object segmentation research, such as mean pixel-wise intersection-over-union (IoU), precision, and recall. While these were useful for iterating on the model, we found them insufficient at capturing many nuances that lead to a compelling and useful product experience. To better measure these, we employed crowd evaluation, where human annotators rated the output of our model on a held-out test set. This allowed us to focus on areas of improvement that would have been difficult to identify using conventional metrics.
Developing the model underlying the subject lifting feature involved a complex interplay of applied research, engineering, and practical considerations. This article highlighted the challenges involved and how we tackled them. By taking full advantage of specialized hardware like the Neural Engine, we’re able to deliver high-quality results with low latencies while still being power efficient. Gauging how well the model performs is a multifaceted task. The quality of segmentation is just one of the many ingredients. Balancing it with fairness and holistic feedback from user studies is key to ensuring a shipping-quality model.
Many people contributed to this research including Saumitro Dasgupta, George Cheng, Akarsh Simha, Chris Dulhanty, and Vignesh Jagadeesh.
“iPhone User Guide — Lift a subject from the photo background on iPhone.” Support.apple.com. [link.]
Tan, Mingxing, and Quoc V. Le. 2021. “EfficientNetV2: Smaller Models and Faster Training.” June. [link]
He, Kaiming, Jian Sun, and Xiaoou Tang. 2013. “Guided Image Filtering.” IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (6): 1397–1409. link.
Learning Iconic Scenes with Differential Privacy
July 21, 2023research area Computer Vision, research area Privacy
In this article, we share how we apply differential privacy (DP) to learn about the kinds of photos people take at frequently visited locations (iconic scenes) without personally identifiable data leaving their device. This approach is used in several features in Photos, including choosing key photos for Memories, and selecting key photos for locations in Places in iOS 17.
On-device Panoptic Segmentation for Camera Using Transformers
October 19, 2021research area Computer Vision, research area Methods and Algorithms
Camera (in iOS and iPadOS) relies on a wide range of scene-understanding technologies to develop images. In particular, pixel-level understanding of image content, also known as image segmentation, is behind many of the app’s front-and-center features. Person segmentation and depth estimation powers Portrait Mode, which simulates effects like the shallow depth of field and Stage Light. Person and skin segmentation power semantic rendering in group shots of up to four people, optimizing contrast, lighting, and even skin tones for each subject individually. Person, skin, and sky segmentation power Photographic Styles, which creates a personal look for your photos by selectively applying adjustments to the right areas guided by segmentation masks, while preserving skin tones. Sky segmentation and skin segmentation power denoising and sharpening algorithms for better image quality in low-texture regions. Several other features consume image segmentation as an essential input.

Our research in machine learning breaks new ground every day.