content type highlightpublished July 21, 2023
Learning Iconic Scenes with Differential Privacy
Learning Iconic Scenes with Differential Privacy
In this article, we share how we apply differential privacy (DP) to learn about the kinds of photos people take at frequently visited locations (iconic scenes) without personally identifiable data leaving their device. This approach is used in several features in Photos, including choosing key photos for Memories, and selecting key photos for locations in Places in iOS 17.
The Photos app learns about significant people, places, and events based on the user’s library, and then presents Memories: curated collections of photos and videos set to music. The key photo for a Memory is influenced by the popularity of iconic scenes learned from iOS users—with DP assurance.
We prioritized three key aspects of the machine learning research powering this feature:
Data changes. Identifying iconic scenes—like popular locations such as Central Park in New York City or the Golden Gate Bridge in San Francisco—and the type of photos people take at those locations allows for better key photo selection. Even so, we want to make Memories a compelling feature for device owners no matter where they are located. In addition, iconic scenes can change over time or depending on the season. For example, if a new dog park opens near the Golden Gate Bridge, people might start taking more photos of dogs in that location. Or, if it is winter, people might be taking pictures of the ice skating rink in Central Park. Identifying a new category of photos in a popular location is a perfect task for a data-driven solution. To preserve user privacy, we want to keep information about where people go and what they see there on their device.
Local versus central differential privacy. DP was designed to learn statistics about data with strong assurances of not leaking personally identifiable information. With these considerations in mind, we started with local DP solutions, as seen in the paper Learning with Privacy at Scale, that implement sufficient protections in the operating system so that researchers could verify our claims by reverse-engineering the code. However, we soon discovered that this approach was limited since local DP requires a significant amount of noise to be added, allowing us to discover only the most prominent signal. We needed a better solution that could provide a transparent and verifiable DP assurance while also improving the utility of the learned histograms.
Nonuniform data density. Data gathered across the world is not uniformly distributed, so the privacy challenges differ across regions. For example, suppose many users take photos in a particular location. This makes learning detailed statistics with high precision and privacy assurances easier and provides more useful results. If fewer users visit other locations and take fewer photos, we have less data to work from. This makes it more difficult to glean a meaningful signal without jeopardizing user privacy. In high-density areas, we could learn better precision (with the same privacy assurance) because there is a bigger crowd to hide in. But we don’t know the distribution (that is, which areas are high or low density).
We combined local noise addition with a technique called secure aggregation to address these concerns of balancing privacy with utility. To understand how balancing privacy with utility works, let’s dive into a Photos Memories use case.
A user takes a photo in a place they visit. The photo is annotated with common categories, such as recreation, person, sky, and so on. The model that assigns those categories runs locally on the user’s device, as described in A Multi-Task Neural Architecture for On-Device Scene Analysis.
If the user opts in to the Analytics & Improvements feature, and enables Location Services and precise location stored on photos, we randomly pick one location-category pair (like Central Park (New York) and person) and encode it into a one-hot vector, as described in Figure 2.
Now, we take this one-hot vector and flip each bit with some probability. The noise introduced by flipped bits provides a local DP assurance, which is later amplified through secure aggregation.
Next, we split this binary vector (one-hot vector with random noise) into two shares. Each share on its own is meaningless noise, but when combined with the other, we get the noised vector back. Each share is encrypted with a different public key and uploaded to the server.
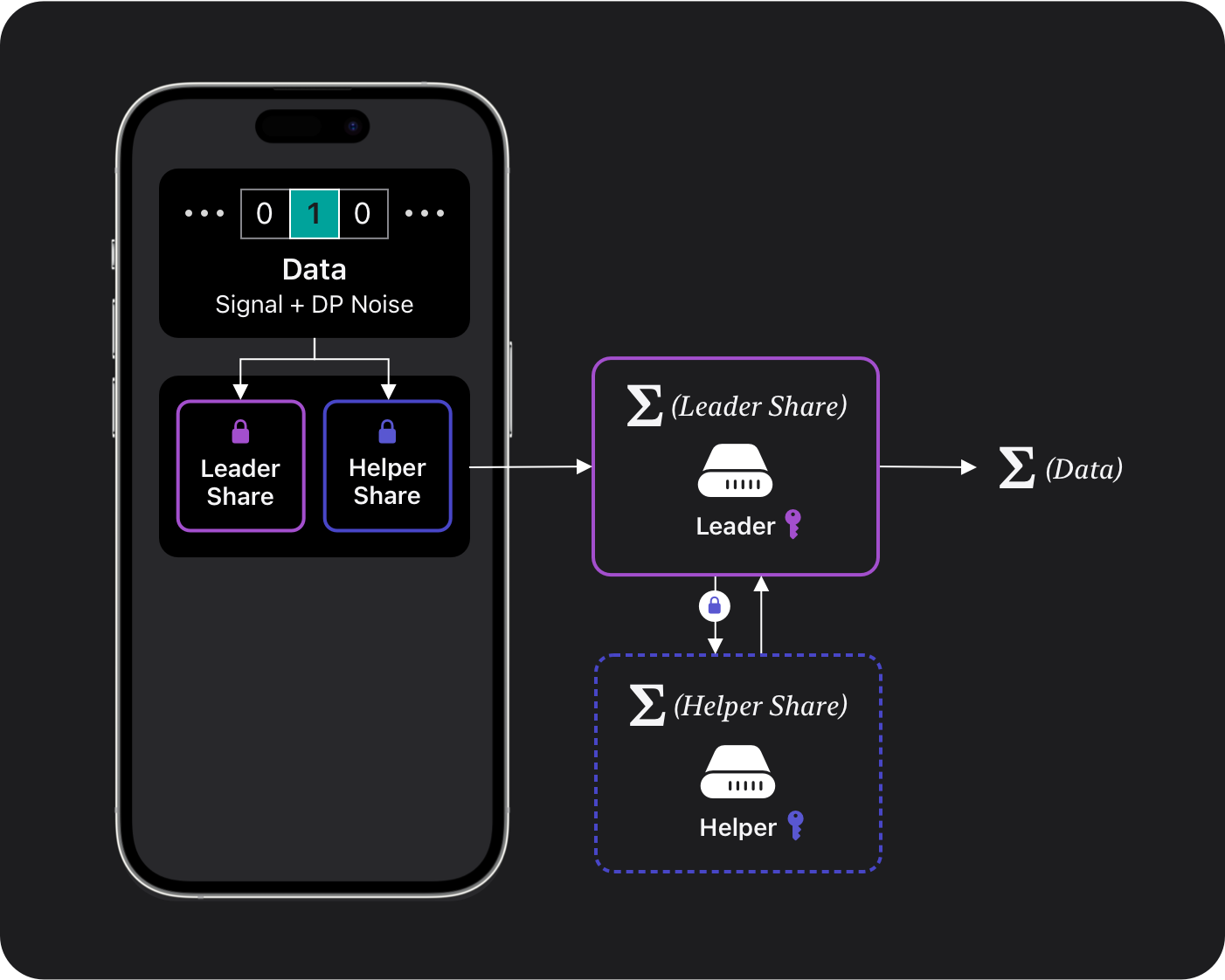
On the server side, there are two main components, as shown in Figure 3:
Both the helper and leader components publish their aggregate only if it satisfies a minimal cohort size (the minimal number of devices contributing their shares). As long as no single entity has access to both private keys, nobody can see the original one-hot vector from any single device. They would see only the aggregates, which satisfies the DP assurance. This DP assurance is enforced through local noise (added on the user device), which gets amplified by secure aggregation, as described in Private Federated Statistics in an Interactive Setting.
Finally, both aggregates from the helper and leader functions are combined to get a noisy aggregate vector from all the devices within the cohort. This vector is decoded back into the location and photo categories, which can then be visualized on a map, as shown in Figure 4.
We needed a solution to address one more complication: Detecting malicious updates would be difficult because nobody can see any single vector. For example, a malicious user might submit vectors to the server that would poison the final histogram. We surmounted this obstacle using Prio validation, as discussed in the work Prio: Private, Robust, and Scalable Computation of Aggregate Statistics.
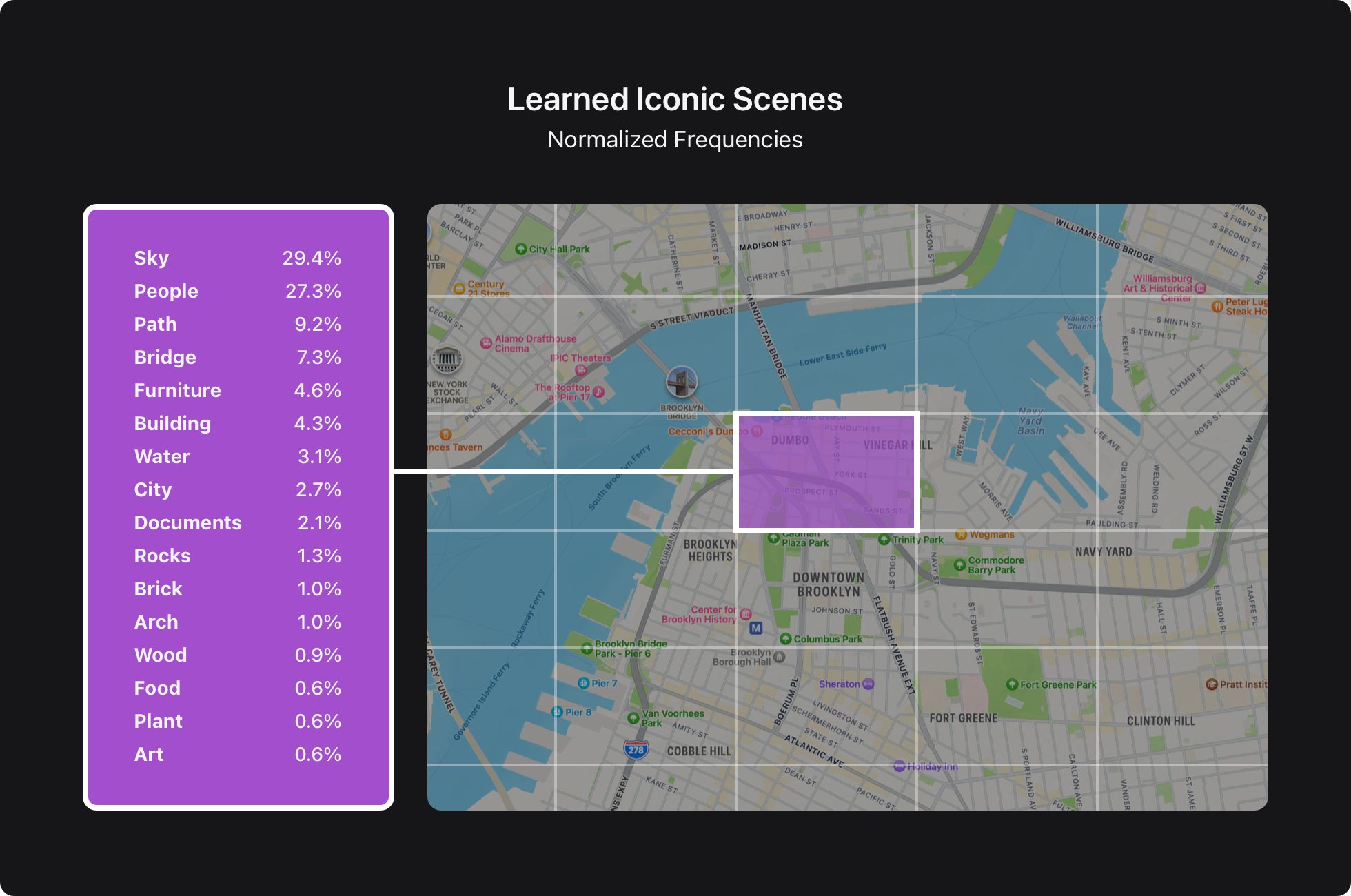
We discovered frequencies for 4.5 million location-category pairs for 1.5 million unique locations and 100 categories using this approach. These frequencies have been powering ML selections of Memories key photos for millions of device owners worldwide since iOS 16, as well as a ranking of photos and locations in Places Map in iOS 17.
The learned histograms satisfy DP . We used a cohort size of 150,000. To avoid dropping histograms with smaller populations, we add additional noise in the secure aggregation protocol to achieve a DP of . To ensure our strong privacy assurance holds without requiring that users trust either the helper or the leader component, this noise is added independently by both the helper and leader components.
Privacy-preserving ML research has already improved user experiences, and this is just the beginning. There are many opportunities to improve our system further, including:
Privacy accounting and transparency. The current approach provides a formal DP assurance for a given histogram. However, DP is composable, and that’s an opportunity to provide an even more precise privacy assurance—one that is not specific to a single task or user data. One of the next steps is exploring formal accounting methods for precise accounting across multiple histograms.
The current approach is compatible with the Distributed Aggregation Protocol developed by the IETF working group, which is publicly available. We would like to open source key components of the system to make it easier, to verify the correctness of our implementation.
Better algorithms. The data is not uniformly distributed. For instance, many people might take pictures in one location, and very few might take photos in other locations. We are limited to fixed precision to provide a consistent privacy assurance with our current approach, which can’t be optimal for all locations. An iterative approach of gradually traversing the data and drilling into more popular places with higher precision will likely bring better results.
Each device has hundreds or thousands of photos with multiple categories, but we pick only one random category from one randomly sampled historical photo. There is an opportunity to develop efficient algorithms for encoding and aggregating multiple location-category pairs to produce more precise histograms while maintaining the same privacy assurance.
Other data science tools. Histograms are very powerful, but to build even better experiences with privacy-preserving ML, we must provide a full set of data science tools. For example, for tasks that have good supervision, gradient-based algorithms might be powerful, along with tools for rigorous statistical testing to compare different solutions. And for tasks where no supervision is available, unsupervised algorithms such as k-means clustering might be needed. Many of those algorithms can be implemented using histograms, but custom solutions often bring significantly better utility, which is key for building better user experiences.
Our goal is to provide an interpretable privacy assurance to our users, in a transparent way. As more users worldwide contribute their photos of iconic scenes in more locations, the resulting datasets will better represent the world’s population, enabling us to build more inclusive experiences.
In this post, we described a step toward that goal, how we learned frequencies of iconic scenes with formal DP assurance. This enabled us to improve key photo selection for Memories in iOS 16, and Places in iOS 17. This approach of applying privacy-preserving machine learning research to real-world problems fuels ML innovation and helps our users keep their data private.
Many people contributed to this research, including Mike Chatzidakis, Junye Chen, Oliver Chick, Eric Circlaeays, Sowmya Gopalan, Yusuf Goren, Kristine Guo, Michael Hesse, Omid Javidbakht, Vojta Jina, Kalu Kalu, Anil Katti, Albert Liu, Richard Low, Audra McMillan, Joey Meyer, Steve Myers, Alex Palmer, David Park, Gianni Parsa, Paul Pelzl, Rehan Rishi, Michael Scaria, Chiraag Sumanth, Kunal Talwar, Karl Tarbe, Shan Wang, and Mayank Yadav.
Apple. “Learning with Privacy at Scale.” n.d. [link.]
Apple Support. “Use Memories in Photos on your iPhone, iPad, or iPod touch.” 2023. [link.]
McMillan, Audra, Omid Javidbakht, Kunal Talwar, Elliot Briggs, Mike Chatzidakis, Junye Chen, John Duchi, et al. 2022. “Private Federated Statistics in an Interactive Setting.” [link.]
“A Multi-Task Neural Architecture for On-Device Scene Analysis.” 2022. Apple Machine Learning Research. [link.]
Corrigan-Gibbs, Henry, and Dan Boneh. 2017. “Prio: Private, Robust, and Scalable Computation of Aggregate Statistics.” March 18, 2017. [link.]
Geoghegan, Tim, Christopher Patton, Eric Rescorla, and Christopher A. Wood. 2023. “Distributed Aggregation Protocol for Privacy Preserving Measurement.” IETF. July 10, 2023. [link.]
At Apple, we believe privacy is a fundamental human right. It’s also one of our core values, influencing both our research and the design of Apple’s products and services.
Understanding how people use their devices often helps in improving the user experience. However, accessing the data that provides such insights — for example, what users type on their keyboards and the websites they visit — can compromise user privacy. We develop system…
A Multi-Task Neural Architecture for On-Device Scene Analysis
June 7, 2022research area Computer Vision, research area Methods and Algorithms
Scene analysis is an integral core technology that powers many features and experiences in the Apple ecosystem. From visual content search to powerful memories marking special occasions in one’s life, outputs (or “signals”) produced by scene analysis are critical to how users interface with the photos on their devices. Deploying dedicated models for each of these individual features is inefficient as many of these models can benefit from sharing resources. We present how we developed Apple Neural Scene Analyzer (ANSA), a unified backbone to build and maintain scene analysis workflows in production. This was an important step towards enabling Apple to be among the first in the industry to deploy fully client-side scene analysis in 2016.

Our research in machine learning breaks new ground every day.