content type highlightpublished October 19, 2021
On-device Panoptic Segmentation for Camera Using Transformers
On-device Panoptic Segmentation for Camera Using Transformers
Camera (in iOS and iPadOS) relies on a wide range of scene-understanding technologies to develop images. In particular, pixel-level understanding of image content, also known as image segmentation, is behind many of the app’s front-and-center features. Person segmentation and depth estimation powers Portrait Mode, which simulates effects like the shallow depth of field and Stage Light. Person and skin segmentation power semantic rendering in group shots of up to four people, optimizing contrast, lighting, and even skin tones for each subject individually. Person, skin, and sky segmentation power Photographic Styles, which creates a personal look for your photos by selectively applying adjustments to the right areas guided by segmentation masks, while preserving skin tones. Sky segmentation and skin segmentation power denoising and sharpening algorithms for better image quality in low-texture regions. Several other features consume image segmentation as an essential input.




These features employ predictions of scene-level elements, like the sky, as well as predictions of subject-level elements, like each person’s body. Semantic segmentation yields a categorical label for each pixel but does not distinguish between different subject-level elements, such as multiple people in the scene. Some features, such as Smart HDR 4, are designed to treat each subject individually, which requires us to go beyond semantic segmentation. Panoptic segmentation unifies scene-level and subject-level understanding by predicting two attributes for each pixel: a categorical label and a subject label. Moreover, jointly modeling scene-level and subject-level elements through panoptic segmentation unlocks efficient and unified modeling of previously disjoint tasks.
Our approach to panoptic segmentation makes it easy to scale the number of elements we predict, for a fully parsed scene, to hundreds of categories. This year we’ve reached an initial milestone of predicting both subject-level and scene-level elements with an on-device panoptic segmentation model that predicts the following categories: sky, person, hair, skin, teeth, and glasses.
In this post, we walk through the technical details of how we designed a neural architecture for panoptic segmentation, based on Transformers, that is accurate enough to use in the camera pipeline but compact and efficient enough to execute on-device with negligible impact on battery life.
Our main goal was to create a network that executes purely on the Apple Neural Engine (ANE), a coprocessor optimized for energy-efficient execution of deep neural networks on Apple devices.
Besides the pure numerical improvements, employing a single ANE segment allows us to participate in a sophisticated camera pipeline, in which many latency-sensitive workloads run in parallel to maximize the utilization of all available coprocessors.
We chose the Detection Transformer (DETR) architecture as our baseline, for its desirable detector design.
First, DETR doesn’t require the postprocessing that most architectures do. In particular, DETR avoids the need for non-maximum suppression (NMS) for removing duplicate predictions and anchor-based coordinate decoding. NMS isn’t required, thanks to the implicit deduplication performed by the Transformer decoder self-attention layers in this model. Anchor-based position decoding isn’t required, thanks to the global (not relative) coordinate regression.
Second, DETR is highly efficient when evaluating regions of interest (RoIs). Two-stage approaches, such as Mask R-CNN, evaluate thousands of anchor-based RoIs before forwarding hundreds of top-ranked proposals to the second stage. We instead constrain the number of RoIs in the original DETR model by an order of magnitude (from its default configuration of 100), and yet obtain negligible degradation in detection performance for our target distribution of images (<5 people in the scene).
Despite the advantages of DETR’s detector, its extension to panoptic segmentation introduces significant computational complexity, and this limits its applicability in resource-constrained environments. In particular, panoptic segmentation introduces an additional convolutional decoder module, batched along the sequence dimension, as indicated by N in Figure 3.
In a forward pass of DETR, each RoI generates a unique segmentation mask. Input to the pass includes a unique set of feature maps from the Transformer module, along with a common set of feature maps from the Convolutional Encoder module.
When processing a large number of RoIs and output resolution is set to a relatively low value, the batched convolutional decoder module is only one of the performance bottlenecks. With higher output resolutions, it becomes the dominant bottleneck. We set our output resolution as high as 384x512 to obtain high-quality segmentation masks. To mitigate the performance bottleneck of DETR at high resolutions, when scaling to large numbers of object queries, we propose HyperDETR.
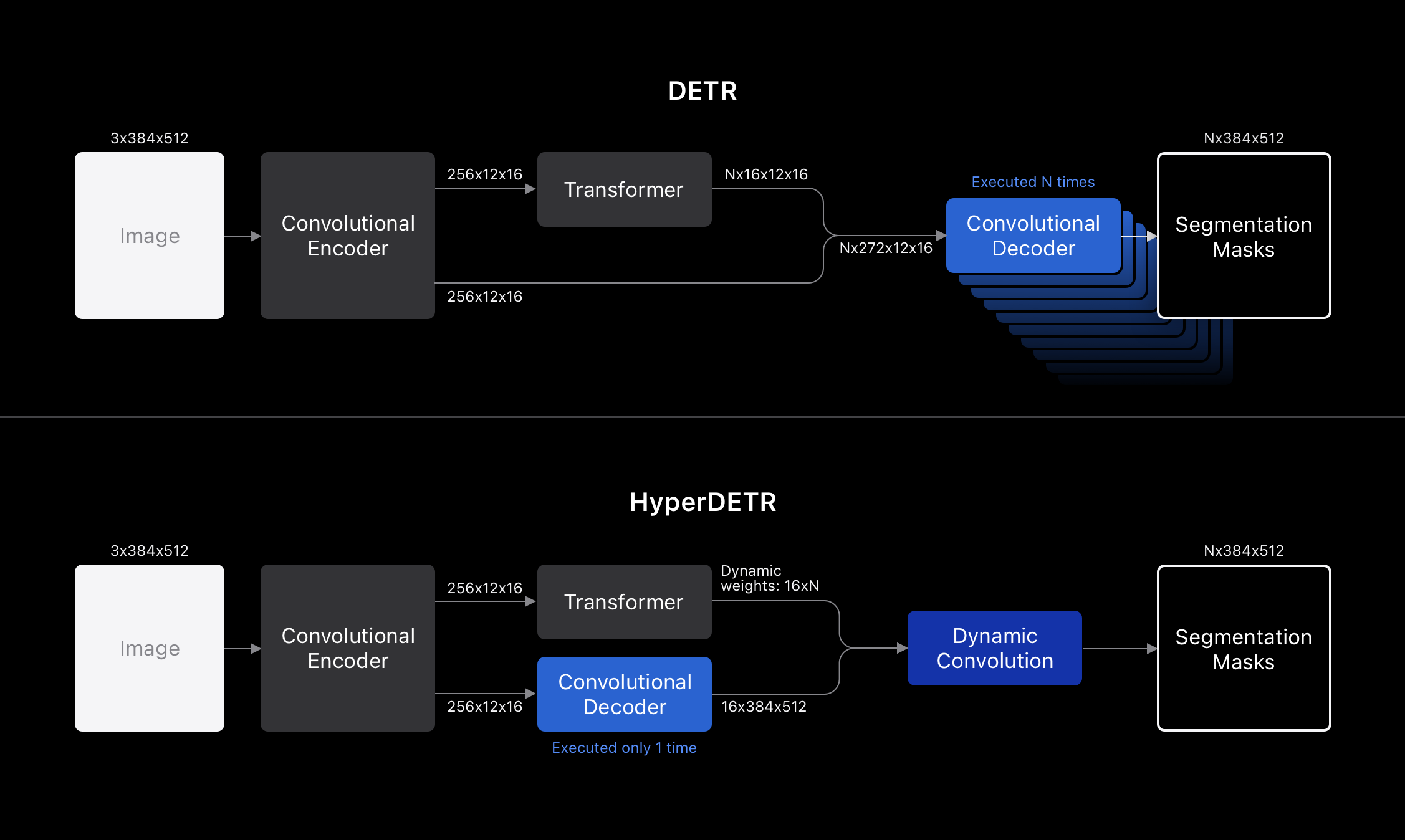
HyperDETR is a simple and effective architecture that integrates panoptic segmentation into the DETR framework in a modular and efficient manner. Inspired by the idea of generating dynamic weights during inference from HyperNetworks, a meta-learning approach, we completely decouple the convolutional decoder compute path from the Transformer compute path until the final layer of the network. The Transformer module’s outputs are interpreted as weight parameters (of shape 16xN) of a dynamic convolution layer with a kernel size of 1x1. The convolutional decoder outputs high-resolution feature maps (of shape 16x384x512) and the dynamic convolution layer linearly combines these two tensors into N unique masks (of shape Nx384x512) as the output of HyperDETR.
The benefits of HyperDETR are twofold.
First, the convolutional decoder can be run without batching along the sequence axis, which decouples the complexity of high-resolution mask synthesis from the RoI sequence length (100 in a standard DETR configuration, 4 in ours).
Second, scene-level categories, such as sky, can be handled purely through the convolutional path, which would let us skip the execution of the Transformer module when subject-level elements are not requested. A side effect of this factorization is that the semantic classes appear in a statically determined output channel, whereas DETR alone might predict semantic classes (such as sky) in multiple partitions across several output channels. A further issue with DETR alone is that the multiplicity of output channels don’t reside at statically determined indexes.
384x512 and the number of RoIs is varied on the x-axis.Concurrent work explores generating dynamic weights through convolutional networks, instead of Transformers. This approach has advantages as well as disadvantages compared to HyperDETR, and an in-depth comparative analysis is subject of future work.
We used the large variant of the MobileNetV3 architecture, with a depth multiplier of 1.5, as the convolutional feature extractor. We pretrained this network on an internal dataset of ~4M images for a multilabel classification task, with roughly 1500 categorical labels.
Next, we removed the final fully-connected layer of the convolutional feature extractor (used for classification during pre-training) and appended a standard Transformer encoder/decoder network for detection, and added a convolutional decoder for segmentation mask regression. The convolutional decoder was constructed using residual blocks with skip connections similar to U-Net. Then, we trained it on another internal dataset of ~50k images that were annotated with extremely high-quality alpha-matte annotations of people, skin, hair, glasses, teeth, and sky.
Before each image was fed into the network during training, we randomly resized, cropped, and resized again. Next, we randomly oriented, randomly rotated, and cropped the valid regions to simulate poorly-oriented captures. Finally, we introduced color jitter by randomly varying brightness, contrast, saturation, and hue.
Building on the order-of-magnitude savings obtained from adopting the HyperDETR architecture, we explored additional optimizations to optimize the memory footprint even further.
First, we applied 8-bit weight quantization to all the model parameters, which reduced the on-device network size from 84MB to ~21MB.
Next, we experimented with various compression techniques such as structured pruning, but finally obtained the best results through a much simpler approach.
We removed the last 4 layers of the 6-layer Transformer decoder module of our HyperDETR network, which resulted in ~4MB of additional savings, to reach a final size of 17MB. We observed negligible change in segmentation quality after removing these layers, because each Transformer decoder layer was already being supervised during training as an early output from the model.
Finally, we leveraged an ANE compiler optimization that splits the computation of layers with large spatial dimensions into small spatial tiles, and makes a trade-off between latency and memory usage. Together, these techniques yielded an extreme reduction in the memory footprint of our model and consequently minimized its impact on battery life and workloads that run in parallel.
In this post, we introduced HyperDETR, a panoptic segmentation architecture that scales efficiently to large output resolutions and a large number of region proposals. Panoptic segmentation, powered by HyperDETR, provides pixel-level understanding for the Camera and enables a wide range of features in the Camera app, such as Portrait mode and Photographic Styles. We designed the model to ensure it is accurate enough to use in the Camera pipeline, but compact and efficient enough to execute on-device without impacting battery life.
If you’re passionate about applying cutting-edge machine learning to image processing applications at Apple, we’d like to hear from you. Discover opportunities for researchers, students, and developers in Machine Learning at Apple here.
Many people contributed to this work including Atila Orhon, Mads Joergensen, Morten Lillethorup, Jacob Vestergaard, and Vignesh Jagadeesh.
Aditya Kusupati, Vivek Ramanujan, Raghav Somani, Mitchell Wortsman, Prateek Jain, Sham Kakade, Ali Farhadi. Soft Threshold Weight Reparameterization for Learnable Sparsity. arXiv:2002.03231, February, 2020, [link].
Alexander Kirillov, Kaiming He, Ross Girschick, Carsten Rother, and Piotr Dollár. Panoptic Segmentation. arXiv:1801.00868, January, 2019. [link].
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam. Searching for MobileNetV3. arXiv:1905.02244, May, 2019. [link].
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jacob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, Illia Polousjin. Attention Is All You Need. arXiv:1706.03762, June, 2017. [link].
David Ha, Andrew Dai, Quoc V. Le. Hypernetworks. arXiv:1609.09106, September, 2016. [link].
Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick. Mask R-CNN. arXiv:1703.06870, March, 2017. [link].
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. arXiv:1512.03385, December 2015. [link].
Nicolas Carion, F. Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko. End-to-end object detection with transformers. arXiv:2005.12872, May, 2020. [link].
Olaf Ronneberger, Philipp Fischer, Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv:1505.04597, May, 2015. [link].
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollár. Microsoft COCO: Common Objects in Context. arXiv:1405.0312, May, 2014. [link].
Xinlong Wang, Rufeng Zhang, Tao Kong, Lei Li, Chunhua Shen. SOLOv2: Dynamic and fast instance segmentation. arXiv:2003.10152, March, 2020. [link].
A Multi-Task Neural Architecture for On-Device Scene Analysis
June 7, 2022research area Computer Vision, research area Methods and Algorithms
Scene analysis is an integral core technology that powers many features and experiences in the Apple ecosystem. From visual content search to powerful memories marking special occasions in one’s life, outputs (or “signals”) produced by scene analysis are critical to how users interface with the photos on their devices. Deploying dedicated models for each of these individual features is inefficient as many of these models can benefit from sharing resources. We present how we developed Apple Neural Scene Analyzer (ANSA), a unified backbone to build and maintain scene analysis workflows in production. This was an important step towards enabling Apple to be among the first in the industry to deploy fully client-side scene analysis in 2016.
Recognizing People in Photos Through Private On-Device Machine Learning
July 28, 2021research area Computer Vision, research area Privacy
Photos (on iOS, iPad OS, and Mac OS) is an integral way for people to browse, search, and relive life’s moments with their friends and family. Photos uses a number of machine learning algorithms, running privately on-device, to help curate and organize images, Live Photos, and videos. An algorithm foundational to this goal recognizes people from their visual appearance.

Our research in machine learning breaks new ground every day.