Scene analysis is an integral core technology that powers many features and experiences in the Apple ecosystem. From visual content search to powerful memories marking special occasions in one’s life, outputs (or "signals") produced by scene analysis are critical to how users interface with the photos on their devices. Deploying dedicated models for each of these individual features is inefficient as many of these models can benefit from sharing resources. We present how we developed Apple Neural Scene Analyzer (ANSA), a unified backbone to build and maintain scene analysis workflows in production. This was an important step towards enabling Apple to be among the first in the industry to deploy fully client-side scene analysis in 2016.
Although most extensively used in the Photos app, other noteworthy adopters of ANSA include:
- Camera, Spotlight search, and Accessibility features
- Apple apps including Notes and Final Cut Pro
- Apps from developers that use Apple’s Vision APIs
Our newest operating systems (iOS 16 and Mac OS Ventura) employ a single backbone that supports multiple tasks completely on-device, and can execute all tasks in tens of milliseconds. Our main priority was to have a state-of-the-art algorithmic workflow delivering world-class user experiences while running all compute fully on the client. Running all compute on a user’s device means ANSA has to operate under tight power and performance constraints, while ensuring various user experiences receive high-quality signals. This allowed us to be discerning with our model’s capacity while meeting user needs. Here are some important factors that influenced our deployment on the device:
- Since devices have limited disk space, deploying multiple tasks was possible only if the backbone was shared and amortized compute and network parameters.
- Scene analysis has to be responsive for interactive use cases, so our latency targets had to be under tens of milliseconds.
- The neural architectures we consider have to be supported on heterogeneous deployment targets. All supported iPhone, iPad, Mac, and Apple TV models have slightly different hardware and compute capabilities, but all must execute ANSA locally. Therefore, we needed to design ANSA in such a way that it could execute efficiently across all applicable device hardware configurations. Although Transformer-based vision backbones are promising, we wanted to offer these capabilities on devices that do not have a Neural Engine. Given this limitation, we chose to utilize architectures built with convolutional layers.
In this article we share on how we train and deploy the network backbone. We begin by providing an overview of the algorithmic considerations as it relates to our legacy and new backbones. Next, we discuss the multihead network performance across various deployment targets, and discuss model quality. Finally, we provide additional context around the experiences powered by these signals.
Supporting Multiple Downstream Tasks with a Systemwide Image-Language Backbone
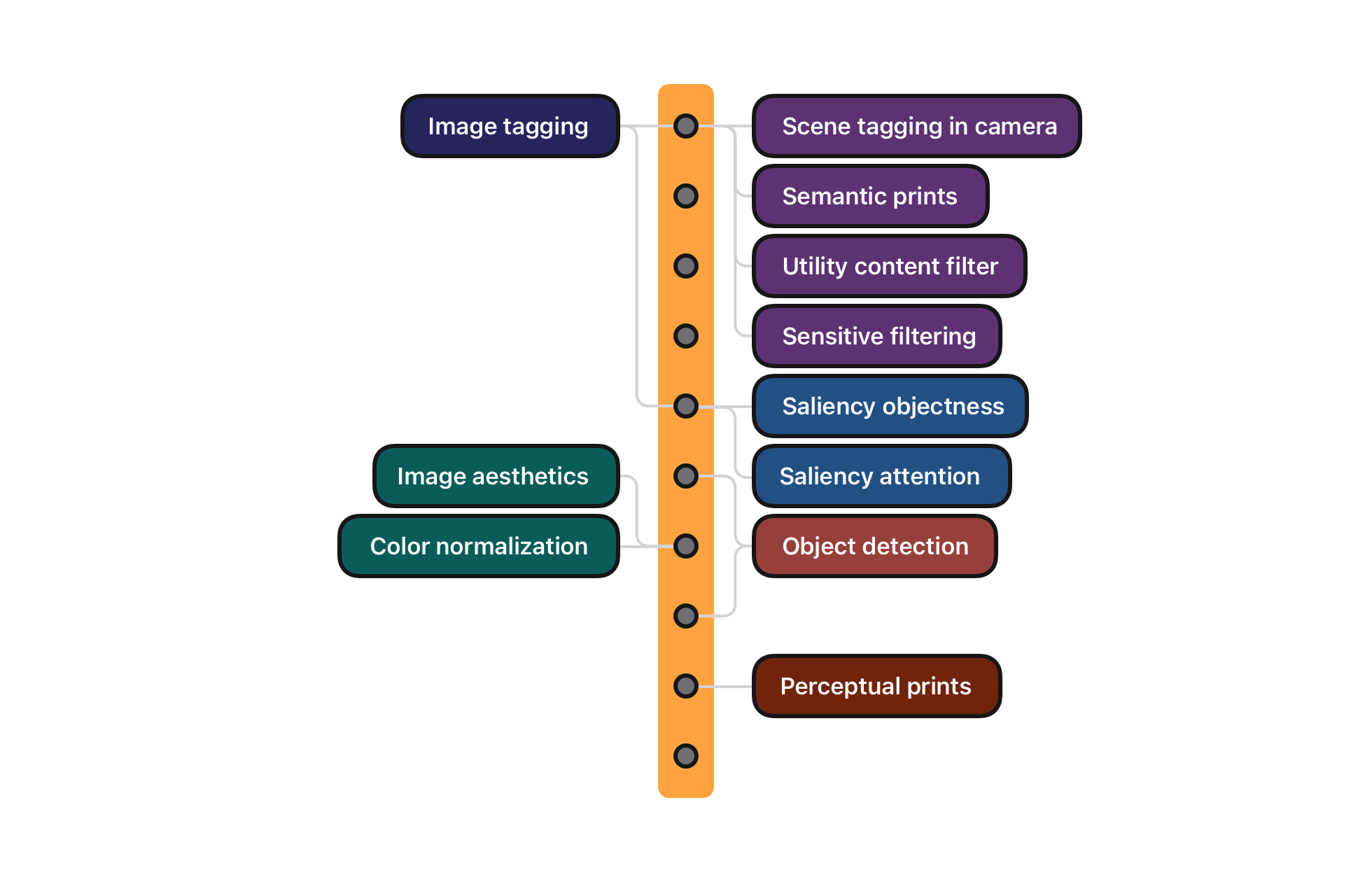
Our goal is to train a high-quality image backbone that can power a large variety of user experiences. Prior to iOS and macOS Ventura, ANSA was designed around a frozen backbone trained with a multilabel classification objective. This choice was intended to yield a robust and universal representation of images for our additional downstream tasks, which were trained separately.
Initially, this classifier was trained on a few million images that included stock imagery. However, recent work has shown that leveraging large-scale weakly supervised data sets can enable state-of-the-art performance on many downstream tasks. These models are trained to jointly embed images with their corresponding natural-language descriptions using a contrastive objective without requiring any high-quality task-specific annotations. Furthermore, these image-language models learn useful representations that can be used for transfer learning on a variety of downstream tasks, while having the ability to perform zero-shot transfer for image tagging in a way that is competitive with fully supervised models. Our newer backbone adopts the joint image-language paradigm and is trained on a few hundred million image-text pairs.
Using large-scale datasets required parallel training on a large number of GPUs (typically hundreds), while employing techniques such as gradient checkpointing and mixed-precision training to maximize the local batch size on each GPU. Furthermore, to ensure the input pipeline doesn’t become a bottleneck, we shard the data set across GPU workers and stored the data set with images resized to a resolution closer to what the model needs for training, enabling faster training throughput (~10x the speed of a base implementation).
With this new image-language pretrained backbone, we transfer learning for other tasks using subnetworks that branch off at various layers in the frozen backbone, as shown in Figure 1. Previously classification was used as the main pre-training objective for the backbone itself, the classification task is now also supported by a small head deployed on top of the image-language backbone. By switching to a MobileNetv3 backbone trained with an image-language objective, we see a 10.5 percent improvement in mean average precision compared to directly using the original classification pretrained backbone. The heads used can vary from a simple linear layer on top of the pretrained image embedding (like the one used for the utility content filter) to a more complex convolutional network connected to different layers in the backbone (like the one used for the object detection). The object detection head adds only 1 MB to the backbone’s disk usage.
On-Device Deployment: Performance Characteristics on the Apple Neural Engine
A critical requirement of ANSA’s design was that all compute takes place on the user’s device, with no involvement of cloud or remote resources. This stipulation imposed several important constraints on the design of ANSA. Namely, the inference must be fast, require a limited amount of memory, use minimal amounts of power, and have as small a footprint on the disk as possible. After a thorough architecture search, we settled on a variant of MobileNetv3, with modifications to better suit the A11 Bionic, M1, and later chips that accelerate machine learning tasks. In its final design, ANSA contains 16 million parameters, is able to execute all of its heads in under 9.7 milliseconds, using only around 24.6 MB of memory on the Apple Neural Engine (ANE), while occupying only around 16.4 MB of disk space. This was achieved through a variety of optimizations, including quantization and pruning techniques.
The text encoder contains 44 million parameters, and is a fairly large model to deploy on the client. We employ a number of techniques to reduce both the model size on disk and the runtime latency and peak memory usage. We employ pruning techniques while fine-tuning the text encoder to remove about 40 percent of model weights without impacting evaluation metrics. Furthermore, we quantize the model weights to 8-bit unsigned integers, which reduces the model size by another factor of four. Utilizing a pruned model allows for faster execution of the model (3-4 ms) on the ANE, and results in a more compact representation of the model on disk.
In Figure 2, we illustrate performance characteristics of the current model in iOS 16; (image-language pretrained), and contrast it with its predecessor in iOS 15 (image classification pretrained). On iPhone 13, we can run the backbone and all its tasks in just under 9.7 milliseconds while utilizing a peak memory of under 24.6 MB. Similarly, in comparison to its predecessor in iOS 15, the new model is significantly faster on the ANE, while demonstrating significant gains on older GPU devices. It also has an impressive 40 percent reduction in peak memory used during inference while requiring less storage on disk. Figure 2 captures the latency and memory profile of the image and text encoders separately.
Considerations for Evaluating Model Quality
We evaluate ANSA through a variety of targeted benchmarks for both the backbone and each downstream task. For the backbone, we evaluate the quality of the joint image-text representation through retrieval metrics using held-out image-text data sets. Additionally, we conduct evaluations based around linear probing and zero-shot accuracy of the pretrained backbone on public benchmarks including ImageNet and COCO. Table 1 shows model quality on relevant ImageNet and Coco benchmarks. We compare ANSA against our internal implementation of a ViT-B-16 based visual encoder that achieves quality that is on par with published state-of-the-art. The compact model leads to a quality hit on public benchmarks, but we found that the visual encoder was meeting task-specific production KPIs.
| Vision architecture | # Parameters (vision) | ImageNet Top-5 Accuracy | Text to Image Coco Top-5 Retrieval Accuracy |
|---|---|---|---|
| ViT-B/16 | 86M | 87.54 | 64.94 |
| MobilenetV3 | 9M | 80.44 | 57.32 |
For each downstream task, we also have task-specific measurements, such as mean average precision (mAP) for our classification task. These are typically performed on a mixture of held-out data and user-representative libraries that are intended to mimic the expected distribution of a typical user’s library. In addition to tracking metrics on our dedicated test sets for each task, we leverage Apple internal testing programs, gathering valuable feedback to complement our analysis with an even larger, evolving, and diverse population.
Prior to shipping, we benchmark our models along different dimensions relevant to the final user experience, especially concerning bias and fairness. We address any soft spots through targeted data collections covering the diverse appearance of subjects, poor lighting, images from older sensors, and changes in resolution, to cite a few. These data sets are built by mining large-scale unlabeled repositories using embedding-based image search, natural language retrieval, and model distance to decision-boundaries. We incorporate this additional data after it has been reviewed carefully by a diverse set of annotators. The annotators correct the identified issues and prevent future regressions in our training and validation sets.
A Few Key User Experiences Leveraging Scene Analysis
The signals generated by ANSA are used in a multitude of experiences across the system including visual search, Featured Photos, Memories that appear in the Photos app and Widget, wallpaper suggestions, deduplication, and scene classification in Camera.
Visual content search is an important use case that is serviced through a fixed taxonomy image tagger. Synonyms of tags in the taxonomy are searchable, while a word-embedding model is used to mitigate null queries suggesting the closest searchable concept. These experiences are accessible through the Photos app and Spotlight. It is worth noting that Spotlight enables search across multiple apps. An example of the entry point into the Photos Search experience is shown in Figure 3.
Memories in the Photos app is an experience that requires detailed visual content understanding. The scene tags from ANSA are ingested in the Photos knowledge graph, which is the foundation of personalized experiences across the user’s photo library. Detecting food, mountains, beaches, birthdays, pets, or hikes helps build a personalized understanding of the user and their interests. This in turn allows for an experience that offers personalized and delightful curated content. Other uses of ANSA include ranking imagery for cover photo selection, titles for generated video memories, and alignment with music content that enhances the experience. The use of image-language embeddings has allowed the discovery of richer memory types that were previously inaccessible through fixed taxonomy tagging. Detecting human-object interactions like people seated around a table is one such use case. As an example, the top left illustration in Figure 3 leverages scene-level tags such as beaches, mountains, and sunsets to generate a personalized Memories movie presentation.
Certain images, containing receipts, documents, and repair references may not be a suited for a variety of Photos features, including Memories, Sharing, and Featured Photos. ANSA has dedicated classifiers to prevent this from happening. The embedding generated by ANSA is used for image deduplication, custom classifiers for utility content filtering, and detection of low-quality image content. Other interesting experiences include intelligent auto-crop for UI placement, image ranking, and training personalized models for recommendation. The image on the bottom right of Figure 3 illustrates Photos curation, which utilizes among other signals, utility content filtering, image tagging and image aesthetics to pick the highest-quality images from the user’s library.
Conclusion
This article provides a closer look into our production scene-analysis workflows. We emphasize deploying neural networks on the user’s device for local and privacy-preserving compute. Our workflows have scaled and have kept pace with advancements in machine learning research over the past six years, overcoming the challenge of running efficiently our networks on the client side while maintaining state-of-the-art quality for our users. This is key to a variety of experiences in the Apple ecosystem that seamlessly utilize scene analysis.
The work shown in this article is a result of years of collaboration between teams across Apple. To ensure ANSA would meaningfully enhance user experiences across the Apple ecosystem, these teams collaborated closely on data collection, modeling, training / deployment infrastructure, model quality and robustness in the field, and the final user experience. This article illustrated some of the unique opportunities for ML research and development in a highly integrated environment, covering aspects ranging from hardware, software engineering, and design. All this is to enable experiences that will positively impact the lives of millions of users.
Acknowledgments
Many people contributed to this research, including Brandon McKinzie, Rohan Chandra, Sachin Ravi, Alp Aygar, Anindya Sarkar, Atila Orhon, Côme Weber, Mandakinee Singh Patel, Sowmya Gopalan, and Vignesh Jagadeesh.
References
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. “Training Deep Nets with Sublinear Memory Cost.” April 2016. [link.]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. “A Simple Framework for Contrastive Learning of Visual Representations.” July 2020. [link.]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. “ImageNet: A Large-Scale Hierarchical Image Database.” 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255. [link.]
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, and Hartwig Adam. “Searching for MobileNetV3.” November 2019. [link.]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, and Tom Duerig. “Scaling Up Visual and Vision-Language Representation Learning with Noisy Text Supervision.” June 2021. [link.]
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. “Microsoft COCO: Common Objects in Context.” February 2015. [link.]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. “Mixed Precision Training.” arXiv:1710.03740 (2017). [link.]
Aaron van den Oord, Yazhe Li, and Orial Vinyals. “Representation Learning with Contrastive Predictive Coding.”arXiv:1807.03748 (2018). [link.]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. “Learning Transferable Visual Models from Natural Language Supervision.” February 2021. [link.]
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. “LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs.” November 2021. [link.]
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. “Conceptual Captions: A Cleaned, Hypernymed, Image Alt-Text Dataset for Automatic Image Captioning.” Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers), Melbourne, Australia, July 15–20, 2018, 2556–256. [link.]
Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl. “Objects as Points.” April 2019. [link.]
Michael Zhu, and Suyog Gupta. “To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression.” November 2017. [link.]
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. “Microsoft COCO: Common Objects in Context.” February 2015. [link.]
Related readings and updates.
On-device Panoptic Segmentation for Camera Using Transformers
Camera (in iOS and iPadOS) relies on a wide range of scene-understanding technologies to develop images. In particular, pixel-level understanding of image content, also known as image segmentation, is behind many of the app's front-and-center features. Person segmentation and depth estimation powers Portrait Mode, which simulates effects like the shallow depth of field and Stage Light. Person and skin segmentation power semantic rendering in group shots of up to four people, optimizing contrast, lighting, and even skin tones for each subject individually. Person, skin, and sky segmentation power Photographic Styles, which creates a personal look for your photos by selectively applying adjustments to the right areas guided by segmentation masks, while preserving skin tones. Sky segmentation and skin segmentation power denoising and sharpening algorithms for better image quality in low-texture regions. Several other features consume image segmentation as an essential input.
Recognizing People in Photos Through Private On-Device Machine Learning
Photos (on iOS, iPad OS, and Mac OS) is an integral way for people to browse, search, and relive life's moments with their friends and family. Photos uses a number of machine learning algorithms, running privately on-device, to help curate and organize images, Live Photos, and videos. An algorithm foundational to this goal recognizes people from their visual appearance.

Discover opportunities in Machine Learning.
Our research in machine learning breaks new ground every day.