content type highlightpublished August 1, 2017
Improving Neural Network Acoustic Models by Cross-bandwidth and Cross-lingual Initialization
AuthorsSiri Team
Improving Neural Network Acoustic Models by Cross-bandwidth and Cross-lingual Initialization
AuthorsSiri Team
Users expect Siri speech recognition to work well regardless of language, device, acoustic environment, or communication channel bandwidth. Like many other supervised machine learning tasks, achieving such high accuracy usually requires large amounts of labeled data. Whenever we launch Siri in a new language, or extend support to different audio channel bandwidths, we face the challenge of having enough data to train our acoustic models. In this article, we discuss transfer learning techniques that leverage data from acoustic models already in production. We show that the representations are transferable not only across languages but also across audio channel bandwidths. As a case study, we focus on recognizing narrowband audio over 8 kHz Bluetooth headsets in new Siri languages. Our techniques help to improve significantly Siri’s accuracy on the day we introduce a new language.
Even if you have only a limited amount of data related to the training domain, the data are valuable. Most of Siri usage happens over wideband audio channels and only a small fraction happens over narrowband channels (for example, 8KHz Bluetooth headsets). In absolute terms, however, a large number of our customers use Siri over narrowband channels. The amount of narrowband Bluetooth audio we can collect before Siri is launched in a new language is limited. Despite that, our goal is to provide the best possible experience to our customers on day one.
In mid 2014 we launched a new speech recognition engine for Siri using deep neural networks (DNN). First introduced in US English, we expanded this engine to 13 languages by mid 2015. To expand successfully, we had to tackle the problem of building high-quality acoustic models using the limited amounts of transcribed data that could be collected before launch. This was true for wideband audio, e.g., collected over iPhone microphones, but even more so for the narrowband audio collected through Bluetooth headsets.
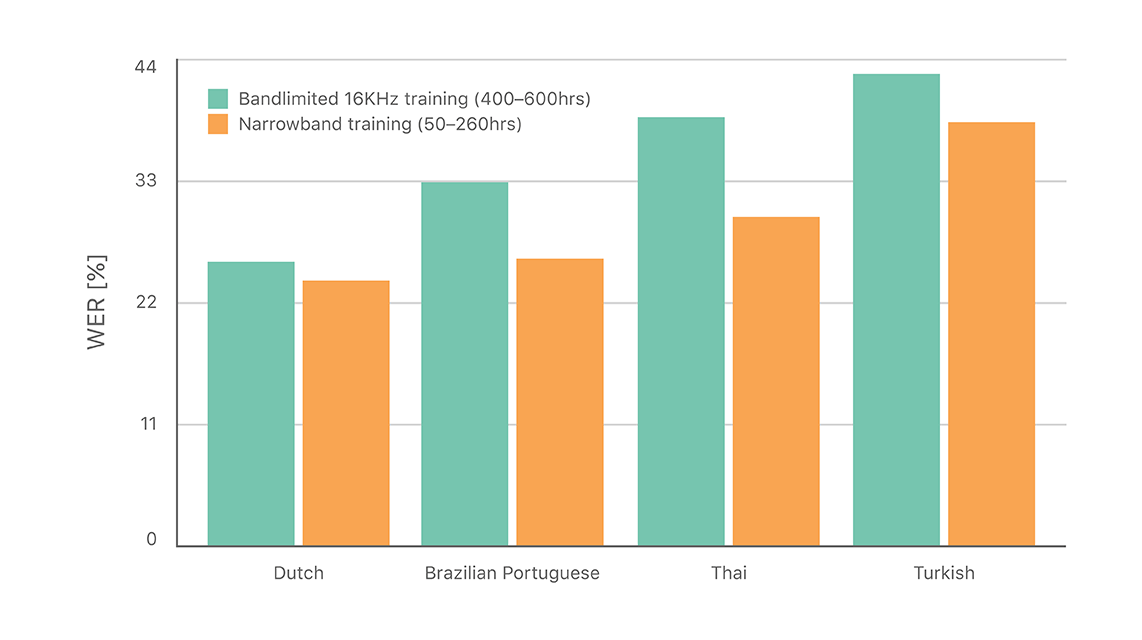
One way we can get around the problem of small amounts of narrowband Bluetooth audio is to band-limit the wideband audio, which is relatively plentiful and easier to collect. In practice, we find that acoustic models trained on limited amounts of narrowband Bluetooth audio still outperform those trained on larger amounts of band-limited wideband audio, highlighting the value of in-domain data in acoustic model training (Figure 1). This calls for leveraging both large amounts of wideband audio and limited narrowband audio. In this work, we investigate neural network initialization, in the framework of transfer learning [1], [2].
Many researchers demonstrated [3] [4] [5] that the hidden layers of a neural network acoustic model may be shared between languages. The reasoning behind this is that the hidden layers learn feature transformations that are less language-specific and instead generalizes between languages.
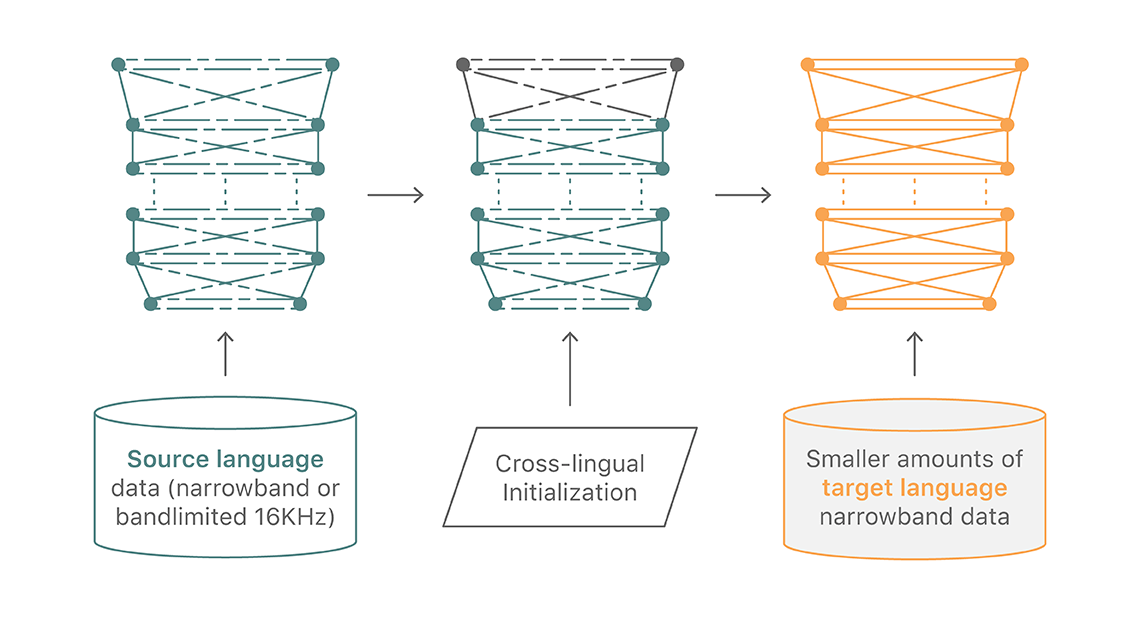
We transfer the hidden layers of a narrowband DNN from a well-trained existing language to the new target language and retrain the network using the target language data, as shown in Figure 2.
Using all available narrowband training data, training with cross-lingual initialization always significantly outperforms the baseline, regardless of the different source DNNs we tried (see [6]). Even with only 20 hours of narrowband data, for most languages, cross-lingual training starting with an English narrowband model outperforms the baseline using much more narrowband data. While we wondered about the role of the linguistic relationship between the source language and the target language, we were unable to draw conclusions.
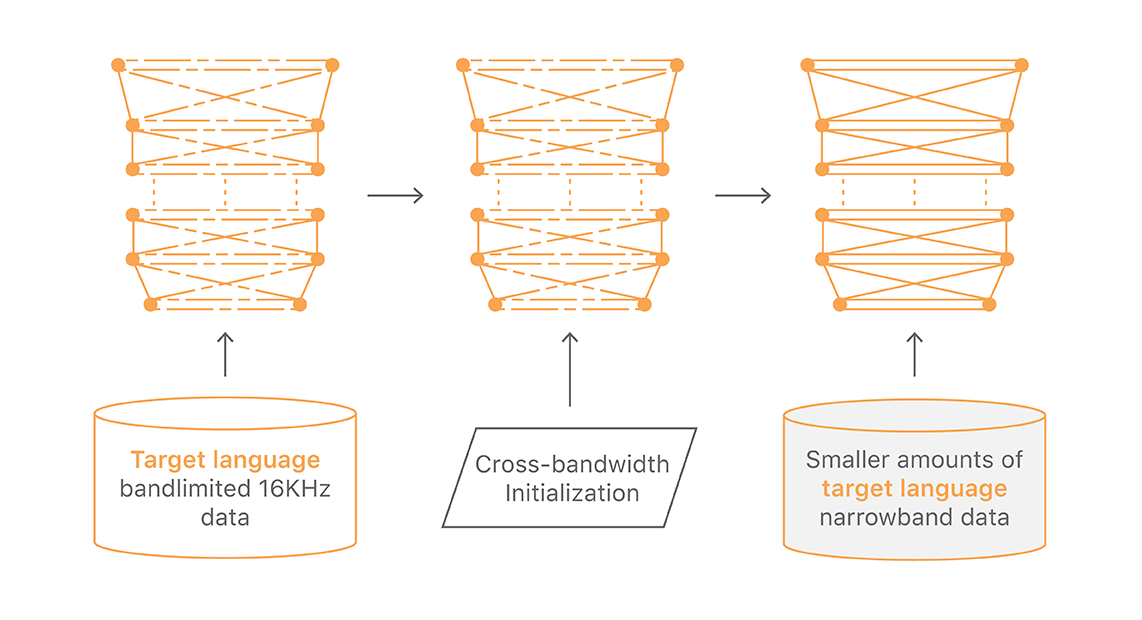
In our initial experiments, we found that models trained using relatively small amounts of real narrowband Bluetooth audio data outperform those trained using larger amounts of band-limited wideband data. However, the band-limited models in a language are still helpful as the initial starting point. We retrain the band-limited model on actual narrowband Bluetooth audio in that language. This way we can use both wideband and narrowband data in a language to train the narrowband models. (Figure 3)
After seeing the success of the previous two transfer learning techniques, we thought we might get further improvement by combining the approaches. Specifically, when initially training a DNN on bandlimited wideband data in a new language, one need not start with random weights, but may initialize the hidden layers from a DNN trained on band-limited data for an already supported language. (See Figure 4.)
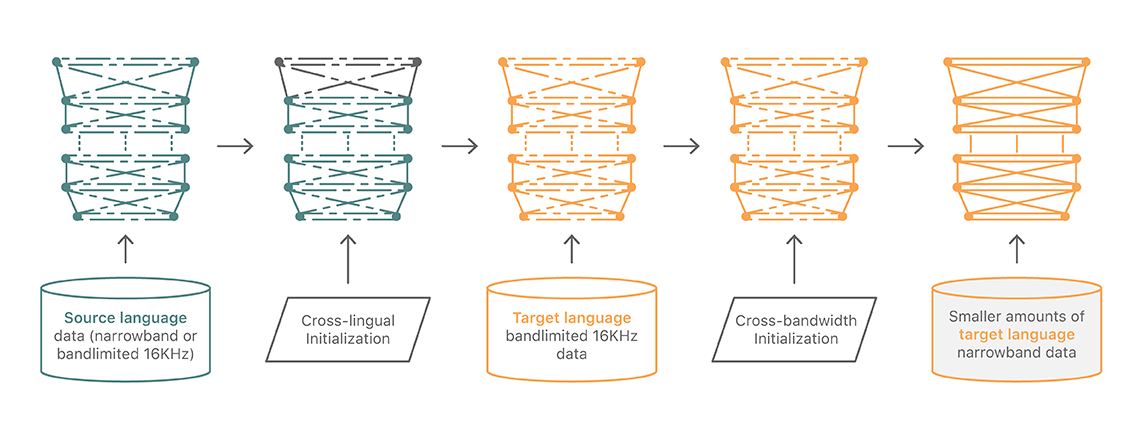
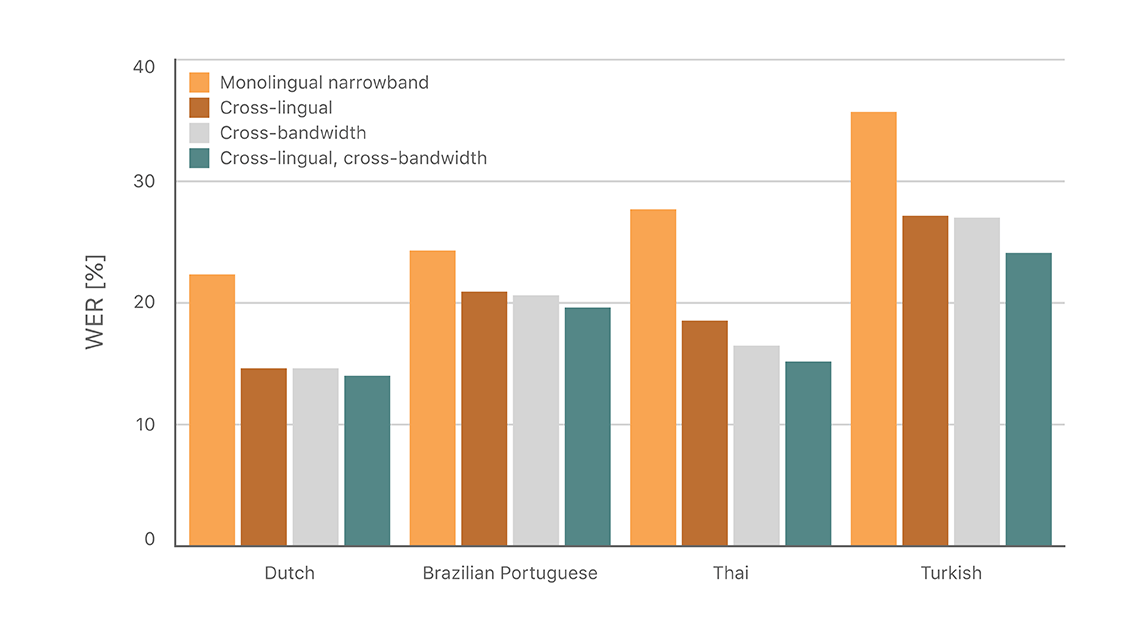
We leverage knowledge from other speech recognition tasks to improve DNN acoustic models for narrowband Bluetooth applications. Such knowledge is obtained through DNN acoustic model initialization, specifically using weights from a previous DNN trained on band-limited wideband data or for a different language.
For all languages in our experiments, these techniques achieve up to 45% relative word error rate (WER) reduction, compared to training solely on Bluetooth narrowband data in the target language. Our approach also provide flexible trade-offs between training time and learning from the most diverse data available, as detailed in our paper [6].
These methods turn out highly effective in many neural network acoustic modeling scenarios beyond the Bluetooth narrowband model case study detailed in this article, and help us build the best possible models when Siri launches in new languages and over new audio channels.
[1] L Pratt, J Mostow, and C Kamm, Direct transfer of learned information among neural networks, in Proceedings of AAAI, 1991.
[2] S Thrun, Is learning the n-th thing any easier than learning the first? in Advances in Neural Information Processing Systems 8 (NIPS-95), 1996.
[3] A Ghoshal, P Swietojanski, and S Renals, Multilingual training of deep neural networks, in Proc. IEEE ICASSP, 2013.
[4] J-T Huang, J Li, D Yu, L Deng, and Y Gong, Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers, in Proc. IEEE ICASSP, 2013.
[5] G Heigold, V Vanhoucke, A Senior, P Nguyen, M Ranzato, M Devin, and J Dean, Multilingual acoustic models using distributed deep neural networks, in Proc. IEEE ICASSP, 2013.
[6] X Zhuang, A Ghoshal, A-V Rosti, M Paulik, D Liu, Improving DNN Bluetooth Narrowband Acoustic Models by Cross-bandwidth and Cross-lingual Initialization, Interspeech, 2017.
Languages You Know Influence Those You Learn: Impact of Language Characteristics on Multi-Lingual Text-to-Text Transfer
December 11, 2022research area Speech and Natural Language ProcessingWorkshop at NeurIPS
Multi-lingual language models (LM), such as mBERT, XLM-R, mT5, mBART, have been remarkably successful in enabling natural language tasks in low-resource languages through cross-lingual transfer from high-resource ones. In this work, we try to better understand how such models, specifically mT5, transfer any linguistic and semantic knowledge across languages, even though no explicit cross-lingual signals are provided during pre-training. Rather,…
Bandwidth Embeddings for Mixed-Bandwidth Speech Recognition
March 26, 2019research area Privacy, research area Speech and Natural Language Processingconference Interspeech
In this paper, we tackle the problem of handling narrowband and wideband speech by building a single acoustic model (AM), also called mixed bandwidth AM. In the proposed approach, an auxiliary input feature is used to provide the bandwidth information to the model, and bandwidth embeddings are jointly learned as part of acoustic model training. Experimental evaluations show that using bandwidth embeddings helps the model to handle the variability…

Our research in machine learning breaks new ground every day.