The “Super Weight:” How Even a Single Parameter can Determine a Large Language Model’s Behavior
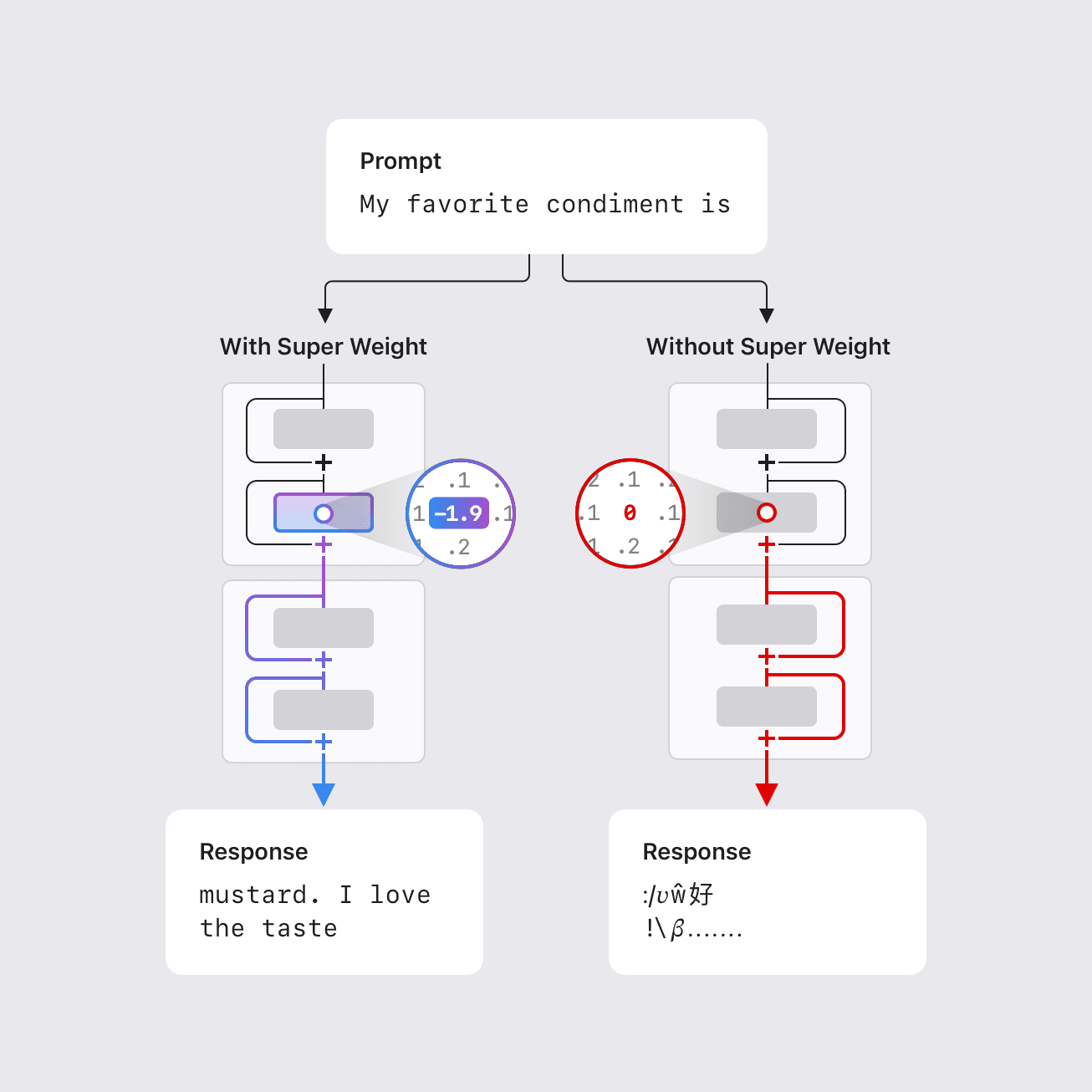
Figure 1: Super Weight Phenomenon: Pruning a single, special scalar, called the “super weight,” can completely destroy a Large Language Model’s ability to generate text. On the left, the original Llama-7B, which contains a super weight, produces a reasonable completion. On the right, after pruning the super weight, Llama-7B generates complete gibberish. This qualitative observation has quantitative impact as well: zero-shot accuracy drops to random and perplexity increases by orders of magnitude.
Figure 1: Super Weight Phenomenon: Pruning a single, special scalar, called the “super weight,” can completely destroy a Large Language Model’s ability to generate text. On the left, the original Llama-7B, which contains a super weight, produces a reasonable completion. On the right, after pruning the super weight, Llama-7B generates complete gibberish. This qualitative observation has quantitative impact as well: zero-shot accuracy drops to random and perplexity increases by orders of magnitude.
A recent paper from Apple researchers, “The Super Weight in Large Language Models,” reveals that an extremely small subset of parameters in LLMs (in some cases, a single parameter) can exert a disproportionate influence on an LLM’s overall functionality (see Figure 1). This work highlights the critical role of these “super weights” and their corresponding “super activations,” offering a new insight into LLM architecture and avenues for efficient model compression. The paper provides full technical details and experimental results; in this post, we provide a high-level overview of the key findings and their implications.
While LLMs demonstrate impressive capabilities, their sheer size, often comprising billions or even hundreds of billions of parameters, presents significant challenges for deployment on resource-constrained hardware such as mobile devices. Reducing the size and computational complexity of LLMs for such platforms leads to corresponding reductions in memory and power consumption, enabling them to operate locally, privately, and without an internet connection. However, understanding the internal mechanisms of LLMs is critical, as naïve compression or simplification can lead to substantial degradation in model quality.
Prior research indicated that a small percentage of parameter outliers in LLMs are vital for maintaining model quality — and if these weights are significantly modified (through compression) or removed entirely (pruned) then the model’s output quality suffers. While this prior work showed that this fraction can be as small as 0.01% of the weights, in models with billions of parameters, this still translates to hundreds of thousands of individual weights. In this work, Apple researchers identified a remarkably small number of parameters, termed “super weights,” that if altered, can destroy an LLM’s ability to generate coherent text, for example, leading to a threefold order of magnitude increase in perplexity and reducing zero-shot accuracy to levels consistent with random guessing. For instance, in the Llama-7B model, removing its single super weight renders the model incapable of producing meaningful output. Conversely, removing thousands of other outlier weights, even those with larger magnitudes than the super weight, results in only marginal quality degradation.
This work proposes a methodology for locating these super weights by requiring only a single forward pass through the model. This method leverages the observation that super weights induce correspondingly rare and large activation outliers, which we term “super activations.” These super activations often appear after the super weight, persist throughout subsequent layers with constant magnitude and position, irrespective of the input prompt, and their channel aligns with that of the super weight. By detecting spikes in the input and output activation distributions of specific model components (e.g., the down projection of the feed-forward network), we can locate the super weights via their corresponding super activation. Intriguingly, the super weight is consistently found in the down projection of the feed-forward network following the attention block, typically in an early layer of the network. We have compiled an index of super weight coordinates for several common, openly available LLMs to facilitate further investigation by the research community.
No.
Coordinates
Llama 7B
2
[3968, 7003]
Llama 13B
2
[2231, 2278]
2
[2231, 6939]
Llama 30B
3
[5633, 12817]
3
[5633, 17439]
10
[5633, 14386]
Llama2 7B
1
[2533, 7890]
Llama2 13B
3
[4743, 7678]
Mistral-7B
v0.1
1
[2070, 7310]
OLMo-1B
0724-hf
1
[1764, 1710]
1
[1764, 8041]
OLMo-7B
0724-hf
1
[269, 7467]
2
[269, 8275]
7
[269, 453]
24
[269, 2300]
Phi-3
mini-4k-instruct
2
[525, 808]
2
[1693, 808]
2
[1113, 808]
4
[525, 2723]
4
[1113, 2723]
4
[1693, 2723]
Table 1: The above layer numbers, layer types, and weight types can be directly applied to
Huggingface models. For example, for Llama-7B on Huggingface, access the super weight using layers[2].mlp.down_proj.weight[3968, 7003].
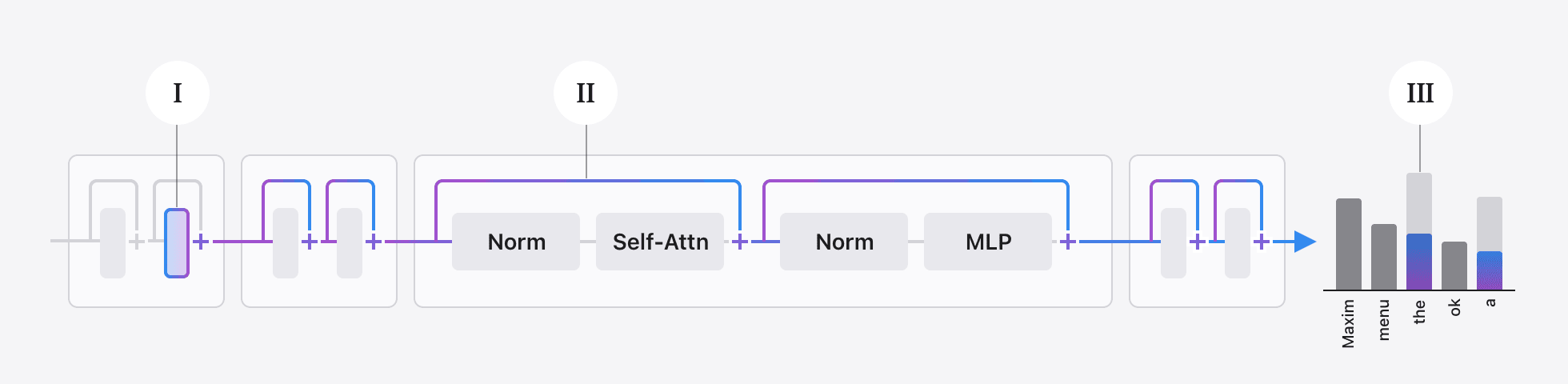
As shown in the coordinates table (see Table 1), super weights emerge in specific projection layers, often early in the network across a wide range of commonly used LLMs. These weights generate a super activation that then persists through the residual skip connections in the network as illustrated in Figure 2. This persistent super activation exerts a global influence on the model’s internal dynamics, biasing it away from generating high-probability stopwords. When super weights are removed, this suppressive effect vanishes, and the model’s output distribution shifts sharply: the likelihood of stopwords increases significantly, while meaningful, content-bearing tokens become less probable. This suggests that super weights play a critical role in determining which semantically meaningful tokens are output during the forward pass of the model.
Figure 2: How Super Weights behave: I: Super weights are often found in an early layer’s down projection, indicated with a blue-purple box. The super weight immediately creates a large-magnitude super activation. II: Super activations are propagated through skip connections, indicated with blue-purple lines. III: This has a net effect of suppressing stopword likelihoods in the final logits. Removing the super weight causes stopword likelihood to skyrocket, indicated with the gray stacked bars.
The discovery of super weights and super activations can lead to improvements in LLM compression and the field’s broader understanding of these models. The large impact of these few parameters suggests that their preservation is critical during LLM compression techniques. We found that by preserving super activations with high precision, simple round-to-nearest quantization methods can achieve performance competitive with more sophisticated state-of-the-art techniques. Similarly, for weight quantization, preserving the super weight while clipping other weight outliers allows round-to-nearest quantization to be effective even with much larger block sizes than previously thought feasible, leading to better compression ratios.
This work demonstrates that handling just a few super outliers can significantly improve compression quality, offering a hardware-friendly approach compared to methods that manage hundreds of thousands of outlier weights. This targeted approach can lead to more efficient models that retain a higher degree of their original performance. This in turn enables powerful LLM applications to operate with high quality on resource constrained hardware, such as mobile devices.
Our findings open several avenues for future research. Further exploration into the genesis and precise mechanisms of super weights and super activations could yield deeper insights into the operational dynamics of LLMs. Understanding how these specific parameters acquire such disproportionate influence during training could inform future model design and training strategies. Investigating the prevalence and characteristics of super weights across a broader array of model architectures and training paradigms can shed light on their role/creation, and the provided directory of super weights aims to spur such continued investigation within the community. Ultimately, a more comprehensive understanding of these super outliers holds the potential to unlock new methodologies for building more efficient, robust, and interpretable LLMs.
Recent works have shown a surprising result: a small fraction of Large Language Model (LLM) parameter outliers are disproportionately important to the quality of the model. LLMs contain billions of parameters, so these small fractions, such as 0.01%, translate to hundreds of thousands of parameters. In this work, we present an even more surprising finding: Pruning as few as a single parameter can destroy an LLM’s ability to generate text —…
In spite of the success of deep learning, we know relatively little about the many possible solutions to which a trained network can converge. Networks generally converge to some local minima—a region in space where the loss function increases in every direction—of their loss function during training. Our research explores why local minima outperforms others when a trained network is evaluated on a held-out test set.