content type paperpublished February 2025
dMel: Speech Tokenization Made Simple
AuthorsHe Bai, Tatiana Likhomanenko, Ruixiang Zhang, Zijin Gu, Zakaria Aldeneh, Navdeep Jaitly
dMel: Speech Tokenization Made Simple
AuthorsHe Bai, Tatiana Likhomanenko, Ruixiang Zhang, Zijin Gu, Zakaria Aldeneh, Navdeep Jaitly
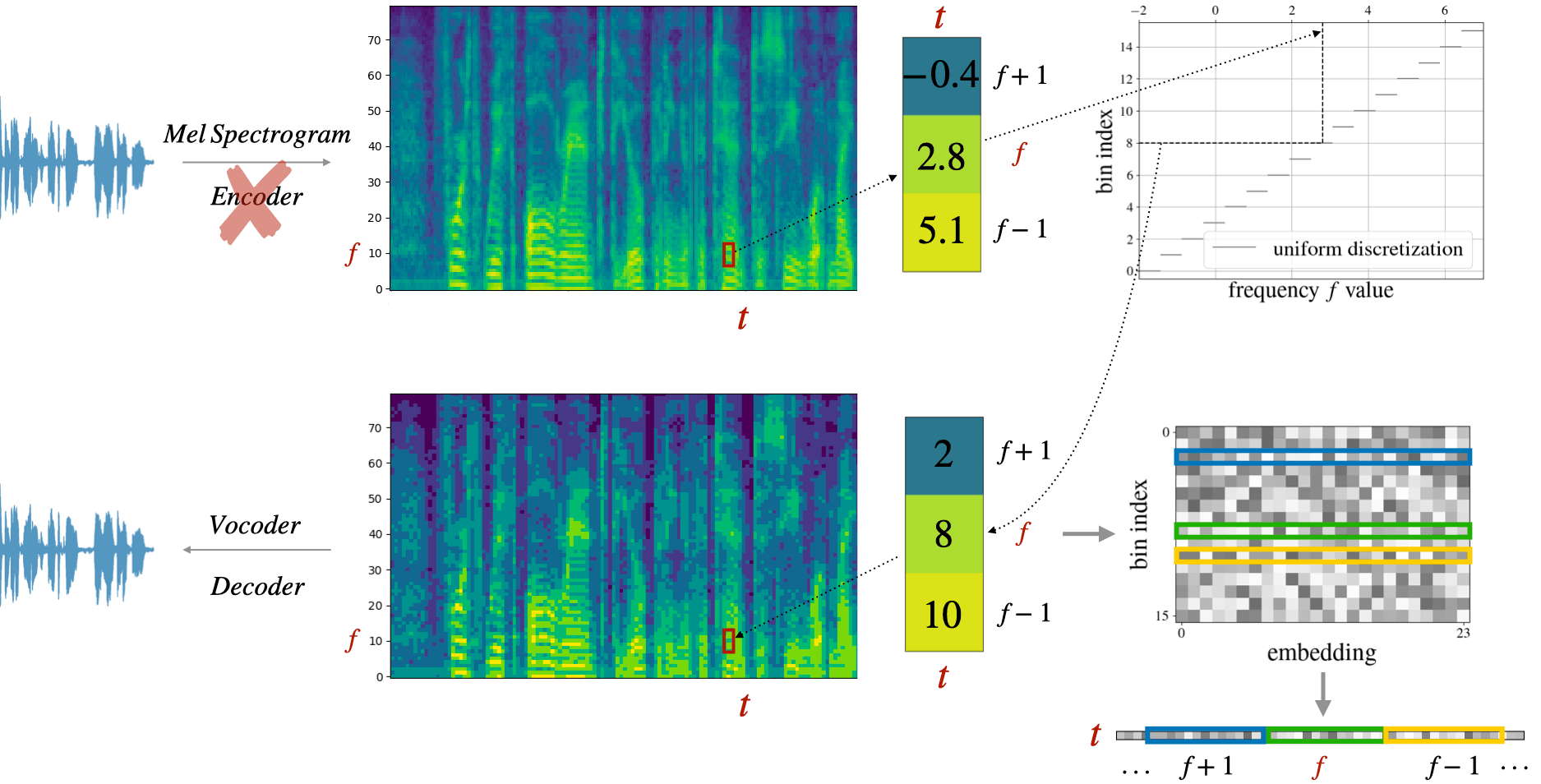
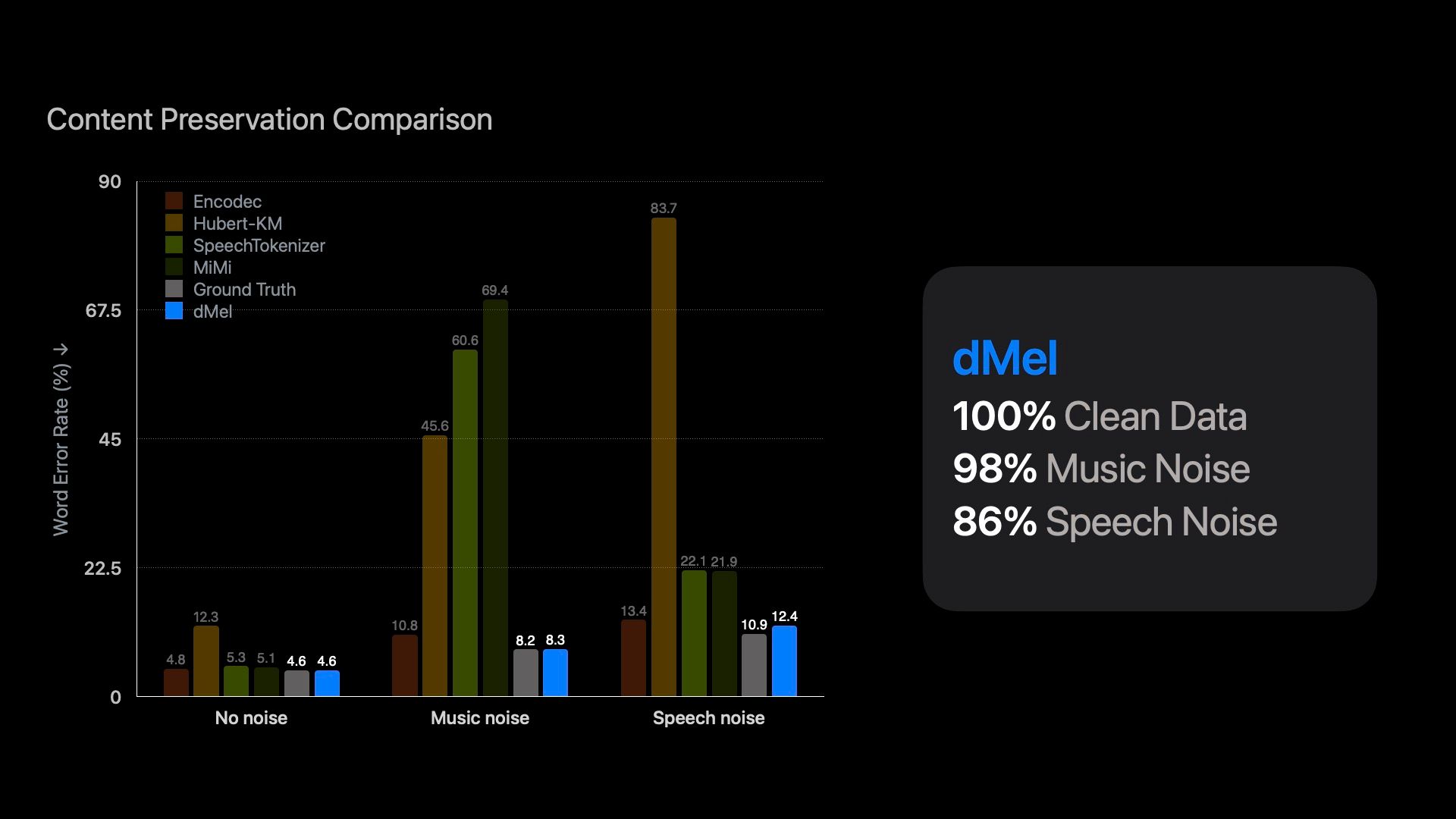
Large language models have revolutionized natural language processing by leveraging self-supervised pretraining on vast textual data. Inspired by this success, researchers have investigated complicated speech tokenization methods to discretize continuous speech signals so that language modeling techniques can be applied to speech data. However, existing approaches either model semantic (content) tokens, potentially losing acoustic information, or model acoustic tokens, risking the loss of semantic (content) information. Having multiple token types also complicates the architecture and requires additional pretraining. Here we show that discretizing mel-filterbank channels into discrete intensity bins produces a simple representation (dMel), that performs better than other existing speech tokenization methods. Using an LM-style transformer architecture for speech-text modeling, we comprehensively evaluate different speech tokenization methods on speech recognition (ASR) and speech synthesis (TTS). Our results demonstrate the effectiveness of dMel in achieving high performance on both tasks within a unified framework, paving the way for efficient and effective joint modeling of speech and text.
Principled Coarse-Grained Acceptance for Speculative Decoding in Speech
January 27, 2026research area Methods and Algorithms, research area Speech and Natural Language Processingconference ICASSP
Speculative decoding accelerates autoregressive speech generation by letting a fast draft model propose tokens that a larger target model verifies. However, for speech LLMs that generate acoustic tokens, exact token matching is overly restrictive: many discrete tokens are acoustically or semantically interchangeable, reducing acceptance rates and limiting speedups. We introduce Principled Coarse-Graining (PCG), which verifies proposals at the…
A Variational Framework for Improving Naturalness in Generative Spoken Language Models
July 11, 2025research area Speech and Natural Language Processingconference ICML
The success of large language models in text processing has inspired their adaptation to speech modeling. However, since speech is continuous and complex, it is often discretized for autoregressive modeling. Speech tokens derived from self-supervised models (known as semantic tokens) typically focus on the linguistic aspects of speech but neglect prosodic information. As a result, models trained on these tokens can generate speech with reduced…

Our research in machine learning breaks new ground every day.