content type highlightpublished May 18, 2023
Improved Speech Recognition for People Who Stutter
Improved Speech Recognition for People Who Stutter
Speech recognition systems have improved substantially in recent years, leading to widespread adoption across computing platforms. Two common forms of speech interaction are voice assistants (VAs) that listen for spoken commands and respond accordingly, and dictation systems, which act as an alternative to a keyboard by converting the user’s open-ended speech to written text for messages, emails, and so on. Speech interaction is especially important for devices with smaller or no screens, such as smart speakers and smart headphones, that support speech interaction. Yet speech presents barriers for many people with communication disabilities such as stuttering, dysarthria, or aphasia.
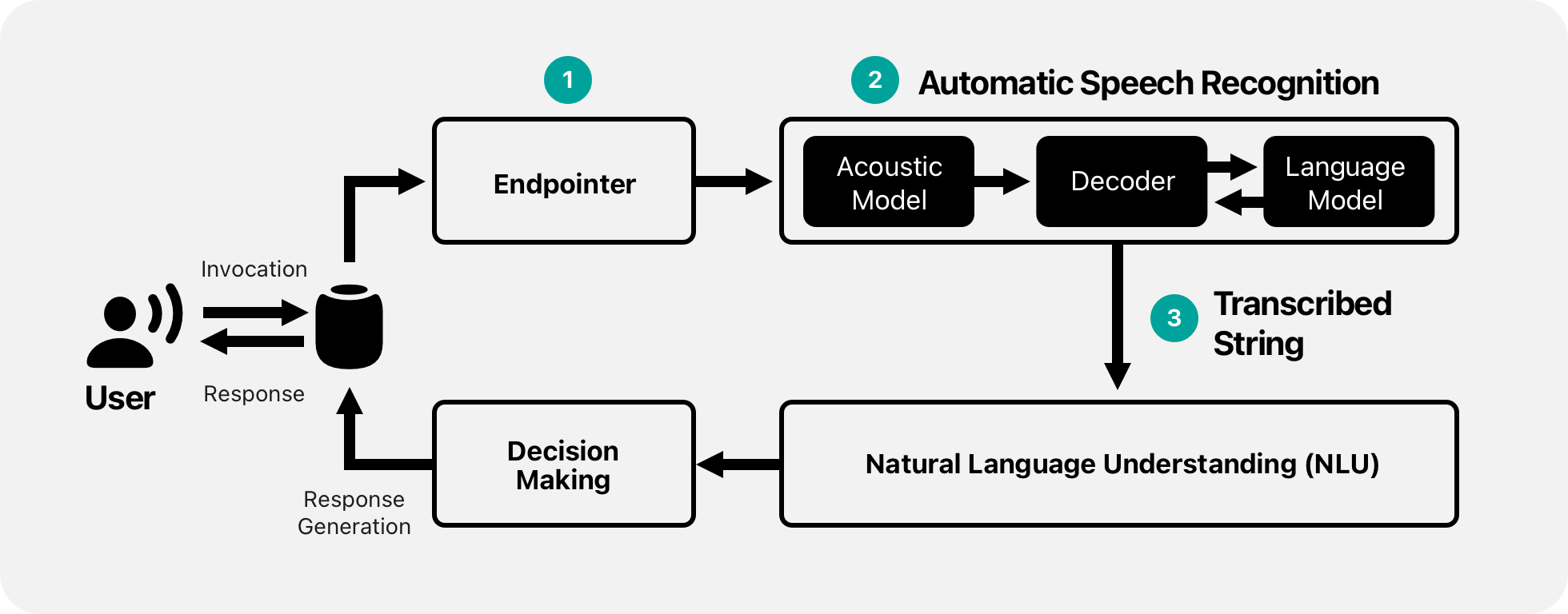
This article focuses on one subset of this population: people who stutter (PWS). We report on user experience and system performance with speech technology for PWS, including a survey on the use of speech technology and an investigation of voice assistant (VA) and dictation system performance. Then, we describe and evaluate three technical solutions that apply production-oriented improvements to a consumer-grade automated speech recognition (ASR) system to better support PWS. The three interventions are shown in Figure 1 within a typical VA pipeline.
Our work to improve speech recognition for PWS is the first to:
Stuttering, also called stammering, impacts approximately 1% of the world’s population, according to the book, “Cluttering: A Handbook of Research Intervention and Education,"" Although estimated incidence ranges from 2% to 5% for subpopulations such as children and males, according to the work, “Epidemiology of Stuttering in the Community across the Entire Life Span.” Stuttering is a breakdown in speech fluency that can affect the rate and flow of speech and can include dysfluency types such as:
Frequent interjections (“um,” “eh”) are also common. The rate, duration, and distribution of these dysfluencies vary substantially between people and across contexts, according to the paper “Variability of Stuttering: Behavior and Impact.”
Research on speech technology for PWS has focused mainly on technical improvements to ASR models, dysfluency detection, and dataset development. The research in the speech recognition field lacks a human-centered approach to understanding the experiences PWS have with speech recognition systems, which could inform how to prioritize and advance technical improvements, according to the work “Exploring Smart Speaker User Experience for People Who Stammer.” One recent exception comes from the paper, “Exploring Smart Speaker User Experience for People Who Stammer,” that included an interview and diary study on the use of VAs with 11 PWS. Their work provides an initial understanding of user experiences with a VA, identifying issues with the device timing out and the influence of social pressure on use. Questions remain, however, about:
Our first goal is to understand the experience of speech technology for PWS, including how well-existing systems work, what challenges arise, and what areas could be improved. In 2022, we conducted an online survey of 61 U.S.-based PWS, all of whom self-identified as having a stutter and were screened by a speech-language pathologist. After listening to their connected speech patterns, the speech-language pathologist used the Andrews & Harris (A&H) scale to assess a dysfluency severity rating, according to the book “The Syndrome of Stuttering.”. Twelve participants were rated as having a mild stutter, 31 as moderate, and 18 as severe.
Many of the 61 PWS used speech technology regularly, albeit at lower rates than the general population. As shown in Figure 2, about half the participants who were familiar with VAs used one daily or weekly, whereas fewer used dictation daily or weekly. By contrast, recent estimates for the general U.S. population suggest 57% use VAs daily and 23% do so weekly, according to the “NPR Smart Audio Report.”
Accessibility challenges. Additionally, the survey characterized accessibility challenges reported by PWS, most notably being cut off or misunderstood by VAs. Plus, stuttering events, such as repetitions and prolongations, result in dictation errors. For example, for the 59 participants familiar with VAs, the most common factors preventing more frequent VA use were:
Indeed, most participants (54.2%, n=32) responded that VAs only sometimes, rarely, or never recognized their speech. Another concern expressed by participants was being cut off too soon by the endpointer, which is the component of the system that predicts when the user is done speaking. Almost half of the participants stated that VAs cut them off always (3.3%, n=2) or often (37.7%, n=23), and 31 of the participants (50.1%) reported being cut off sometimes or rarely.
Nontechnical concerns. Beyond these accessibility challenges, some participants reported other concerns with speech technology. Of the 59 people who were familiar with VAs:
Although many participants were interested in using future technologies that could better recognize stuttered speech, a subset of PWS preferred not to use speech input.
Building on findings from the survey, we turned to recorded speech data from 91 PWS. We quantified how dysfluencies manifest in recognition errors. We also investigated interventions at three stages of the speech pipeline shown in Figure 1:
We focused on interventions that build on pretrained production-grade models, as opposed to training from scratch, so we could optimize on relatively small amounts of data from PWS. To gather this speech data, we asked participants to record themselves speaking 121 VA commands (for example, “What is the weather?”) and up to 10 dictation phrases that consisted of fake text messages the participant might send to a friend. The 50 participants in Phase 1 enrolled starting in 2020, and 41 Phase 2 participants in 2021. Participants in Phase 1 had A&H stuttering severity ratings of the following: A&H stuttering severity ratings: 25 mild, 18 moderate, and seven severe. Phase 2 included participants with zero mild, 26 moderate, and 15 severe ratings.
For the upcoming experiments, we employed baseline models sourced from the Apple Developer Documentation - Speech Framework, which uses a hybrid deep neural network architecture for its ASR system. The papers “SNDCNN: Self-Normalizing Deep CNNs with Scaled Exponential Linear Units for Speech Recognition” and our publication “From User Perceptions to Technical Improvements” details the ASR model which is composed of an acoustic model, a language model, and a beam search decoder.
An endpointer model identifies when the user stops speaking and must balance the desire for a low truncation rate (that is, the percentage of utterances that are cut off too early) with the desire for a minimal delay after speech (the time from the end of the utterance to when the VA stops listening).
Our baseline model is trained on completed utterances from the general population. The baseline model predicts the end of a query using both auditory cues, like how long the user has been silent, as well as ASR cues, such as the likelihood of a given word being the final word of an utterance. The model outputs the likelihood of utterance completion for each input frame (time window). Once the likelihood exceeds a defined threshold calculated to achieve a 3% truncation rate on general population speech, the system stops listening and moves on to the next processing phase.
To improve the VA experience for PWS, we compared this baseline to three new endpointer thresholds tuned on speech from PWS. Using our Phase 1 data, we computed three new, higher threshold values that target an average 3% truncation rate for Phase 1 participants with different A&H stuttering severity ratings:
Raising the endpointer threshold (for example, from the baseline to a higher tuned threshold) reduces the truncation rate but, at the same time, increases the length of time the VA listens before responding.
We evaluated these three new thresholds and the baseline endpointer model on the Phase 2 participant data. As shown in Figure 3, the new thresholds substantially reduce the truncation rate for PWS compared to the baseline.
Across the 41 Phase 2 participants, the baseline endpointer model truncated on average 23.8% of utterances (SD=19.7, median=16.8, interquartile range (IQR)=29.0), vastly higher than the 3% target for that model on general population speech. The tuned endpointers, in contrast, significantly reduced truncation rates. Even the smallest raised threshold—the mild threshold—reduced the truncation rate to a per-participant average of 4.8% (SD=6.4, median=1.5, IQR=6.5), while the moderate threshold achieved our goal of under 3% on average (M=2.5%, SD=3.6, median=0.8, IQR=3.1).
Consumer ASR systems are commonly trained on thousands of hours of speech from the general public, an amount far larger than can likely be obtained from PWS. However, an initial investigation in the work “Analysis and Tuning of a Voice Assistant System for Dysfluent Speech” on 18 PWS showed it may be possible to tune a small number of ASR decoder parameters to improve performance for PWS. Here, we validated that approach on our larger dataset and found even greater gains when tuning on a subset of data from our 50 Phase 1 participants. This approach increases the importance of the language model relative to the acoustic component in the decoder and increases the penalty for word insertions. These changes reduce the likelihood of predicting extraneous low-confidence words often caused by part-word repetitions and bias the model toward more likely VA queries. We used Phase 1 data to tune these parameters and report results in Phase 2.
As shown in Figure 4, the system’s average word error rate (WER) across Phase 2 participants dropped from 25.4% with the baseline to 12.4% with the tuned decoder (SD=12.3, median=6.1, IQR=13.1), a relative improvement of 51.2%. A Wilcoxon signed rank test — used to compare two related samples or matched pairs — showed that this improvement is statistically significant. We also examined how WER improves as a function of dysfluency type. For example, the error rate was lower (improved) in 43.2% of utterances with part-word repetitions and higher (worsened) in 3.9% of utterances. For ASR tuning, WER improved the most in utterances with whole-word repetitions, part-word repetitions, and interjections; the error rate improved the least for utterances with prolongations or blocks.
According to our survey, PWS are often displeased when seeing repeated words, phrases, and filler words in their dictated notes and texts. To address this issue, we refined the transcribed ASR output using two strategies. First, we looked at filler words such as “um,” “eh,” “ah,” “uh,” and minor variations. Many of these fillers are not explicitly defined in the language model (that is, by design, “eh” is never predicted), but in practice, short fillers are frequently transcribed as the word “oh.” As part of our approach, we removed “oh” from predictions unless “oh” is used to represent the number zero. We considered other filler words, such as “like” and “you know,” which are common in conversation. However, they did not appear as fillers in our dataset because the utterances tended to be short and more defined than free-form speech.
Second, we removed repeated words and phrases, which proved challenging because words might naturally be repeated (for example, “We had had many discussions”). We identified all consecutive repeated words or phrases in an ASR transcript and calculated their statistical likelihood of appearing together in text. The calculation was performed using an n-gram language model, which shares similarities with the model described in the paper, “Scalable Modified Kneser-Ney Language Model Estimation.” If the probability was below a threshold, that is, , then we removed the duplicate. Note that these two strategies — interjection removal and repetition removal — can be applied to any ASR model output. Thus, we evaluated our dysfluency refinement approach in combination with the baseline ASR model and the ASR model with the tuned decoder.
As shown in Figure 4, dysfluency refinement reduced WER for the Phase 2 data compared to both the baseline and tuned ASR models. The average WER went from a baseline of 25.4% to 18.1% (SD=19.2, median=6.1, IQR=22.8) after dysfluency refinement — a 28.7% relative improvement on average. The improvement was significant with a Wilcoxon signed rank test (W=839, Z=5.43, ). We further examined the impacts of this refinement step on subsets of utterances in the Phase 2 dataset that contained different types of dysfluencies. The WER improved for 64.7% of utterances that included whole-word repetitions and regressed for only 0.3% of utterances. For utterances with interjections, WER improved in 30.9% of the utterances and regressed in none. Applying dysfluency refinement to the output from the tuned ASR model further reduced WER, from on average 12.5% with the tuned model alone to 9.9% (SD=8.8, median=5.3, IQR=10.3) for the tuned model with dysfluency refinement. Compared to the baseline ASR model, this combination of the tuned model with dysfluency refinement resulted in an average 61.2% improvement across participants.
Our findings demonstrate the contrasting experiences that PWS encounter with speech technologies, and an overall strong interest in improved speech input accessibility from most survey participants. Primary accessibility challenges reflected in both the survey and the baseline speech-recognition performance included being cut off too early (with VAs) and ASR accuracy issues (with both VAs and dictation). We investigated three technical interventions to address these issues:
Although some PWS may not be interested even in improved speech recognition (for example, due to the physical effort required to speak or concern about others overhearing them), these technical interventions hold promise for many others.
Many people contributed to this article, including Colin Lea, Zifang Huang, Lauren Tooley, Jaya Narain, Dianna Yee, Panayiotis Georgiou, Tien Dung Tran, Jeffrey P. Bigham, Leah Findlater, Shrinath Thelapurath, Zeinab Liaghat, Hannah Gillis Coleman, Adriana Hilliard, and Carolyn Feng.
“Apple Developer Documentation, Speech Framework.” n.d. Developer.apple.com. [link.]
Lea, Colin, Huang, Zifang, Tooley, Lauren, Narain, Jaya, Jee, Dianna, Georgiou, Panayiotis, Tran, Tien Dung, Bigham, Jeffrey P., Findlater, Leah. 2023. “From User Perceptions to Technical Improvement: Enabling People Who Stutter to Better Use Speech Recognition.” February. [link.]
Lea, Colin, Vikramjit Mitra, Aparna Joshi, Sachin Kajarekar, and Jeffrey P. Bigham. 2021. “SEP-28k: A Dataset for Stuttering Event Detection from Podcasts with People Who Stutter.” February. [link.]
Mitra, Vikramjit, Zifang Huang, Colin Lea, Lauren Tooley, Sarah Wu, Darren Botten, Ashwini Palekar, et al. 2021. “Analysis and Tuning of a Voice Assistant System for Dysfluent Speech.” June. [link.]
Anantha, Raviteja, Srinivas Chappidi, and Arash W Dawoodi. 2020. “Learning to Rank Intents in Voice Assistants.” April. [link.]
Andrews, Gavin. 1964. The Syndrome of Stuttering. London: Spastics Internat. Med. Publ. [link.]
Ballati, Fabio, Fulvio Corno, and Luigi De Russis. 2018. “Assessing Virtual Assistant Capabilities with Italian Dysarthric Speech.” October. [link.]
Bayerl, Sebastian P., Alexander Wolff von Gudenberg, Florian Hönig, Elmar Nöth, and Korbinian Riedhammer. 2022. “KSoF: The Kassel State of Fluency Dataset — a Therapy Centered Dataset of Stuttering.” June. [link.]
Bleakley, Anna, Daniel Rough, Abi Roper, Stephen Lindsay, Martin Porcheron, Minha Lee, Stuart Nicholson, Benjamin Cowan, and Leigh Clark. 2022. “Exploring Smart Speaker User Experience for People Who Stammer.” October. [link.]
Bleakley, Anna, Daniel Rough, Abi Roper, Stephen Lindsay, Martin Porcheron, Minha Lee, Stuart Alan Nicholson, Benjamin R. Cowan, and Leigh Clark. 2022. “Exploring Smart Speaker User Experience for People Who Stammer.” The 24th International ACM SIGACCESS Conference on Computers and Accessibility, October. [link.]
Craig, Ashley, Karen Hancock, Yvonne Tran, Magali Craig, and Karen Peters. 2002. “Epidemiology of Stuttering in the Community across the Entire Life Span.” Journal of Speech, Language, and Hearing Research 45 (6): 1097–1105. [link.]
Das, Arun, Jeffrey Mock, Henry Chacon, Farzan Irani, Edward Golob, and Peyman Najafirad. 2020. “Stuttering Speech Disfluency Prediction Using Explainable Attribution Vectors of Facial Muscle Movements.” October. [link.]
Fok, Raymond, Harmanpreet Kaur, Skanda Palani, Martez E. Mott, and Walter S. Lasecki. 2018. “Towards More Robust Speech Interactions for Deaf and Hard of Hearing Users.” Proceedings of the 20th International ACM SIGACCESS Conference on Computers and Accessibility, October. [link.]
Gondala, Sashank, Lyan Verwimp, Ernest Pusateri, Manos Tsagkias, and Christophe Van Gysel. 2021. “Error-Driven Pruning of Language Models for Virtual Assistants.” February. [link.]
Heafield, Kenneth, Ivan Pouzyrevsky, Jonathan Clark, and Philipp Koehn. 2013. “Scalable Modified Kneser-Ney Language Model Estimation.” August. [link.]
Heeman, Peter A., Rebecca Lunsford, Andy McMillin, and J Scott Yaruss. 2016. “Using Clinician Annotations to Improve Automatic Speech Recognition of Stuttered Speech.” September. [link.]
Howell, Peter, Stephen Davis, and Jon Bartrip. 2009. “The UCLASS archive of stuttered speech.” 10.1044/1092-4388(07-0129), September. [link.]
Huang, Zhen, Tim Ng, Leo Liu, Henry Mason, Xiaodan Zhuang, and Daben Liu. 2020. “SNDCNN: Self-Normalizing Deep CNNs with Scaled Exponential Linear Units for Speech Recognition.” October. [link.]
Kourkounakis, Tedd, Amirhossein Hajavi, and Ali Etemad. 2020. “Detecting Multiple Speech Disfluencies Using a Deep Residual Network with Bidirectional Long Short-Term Memory.” May. [link.]
MacDonald, Bob, Pan-Pan Jiang, Julie Cattiau, Rus Heywood, Richard Cave, Katie Seaver, Marilyn Ladewig et al. 2021. “Disordered Speech Data Collection: Lessons Learned at 1 Million Utterances from Project Euphonia,” October. [link.]
Mendelev, Valentin,Tina Raissi, Guglielmo Camporese, and Manuel Giollo. 2020. “Improved Robustness to Disfluencies in RNN-Transducer Based Speech Recognition,” December. [link.]
National Public Media. 2022. “NPR Smart Audio Report,” June. [link.]
Ratnera, Nan Bernstein, and Brian MacWhinney. 2018. “Fluency Bank: A new resource for fluency research and practice,” March. [link.]
Roper, Abi, Stephanie Wilson, Timothy Neate, and Jane Marshall. 2019. “Speech and Language.” [link.]
Sander, Eric K, 1963. “Frequency of Syllable Repetition and ‘Stutterer’ Judgments,” February. [link.]
Tichenor, Seth E., and J. Scott Yaruss. 2021. “Variability of stuttering: Behavior and impact.” November. [link.]
Ward, David, and Kathleen S Scott. 2011. Cluttering: A Handbook of Research. Intervention and Education. Psychology Press, 2011. [link.]
From User Perceptions to Technical Improvement: Enabling People Who Stutter to Better Use Speech Recognition
March 14, 2023research area Accessibility, research area Speech and Natural Language Processingconference CHI
Consumer speech recognition systems do not work as well for many people with speech differences, such as stuttering, relative to the rest of the general population. However, what is not clear is the degree to which these systems do not work, how they can be improved, or how much people want to use them. In this paper, we first address these questions using results from a 61-person survey from people who stutter and find participants want to use…
Analysis and Tuning of a Voice Assistant System for Dysfluent Speech
July 9, 2021research area Speech and Natural Language Processingconference Interspeech
Dysfluencies and variations in speech pronunciation can severely degrade speech recognition performance, and for many individuals with moderate-to-severe speech disorders, voice operated systems do not work. Current speech recognition systems are trained primarily with data from fluent speakers and as a consequence do not generalize well to speech with dysfluencies such as sound or word repetitions, sound prolongations, or audible blocks. The…

Our research in machine learning breaks new ground every day.