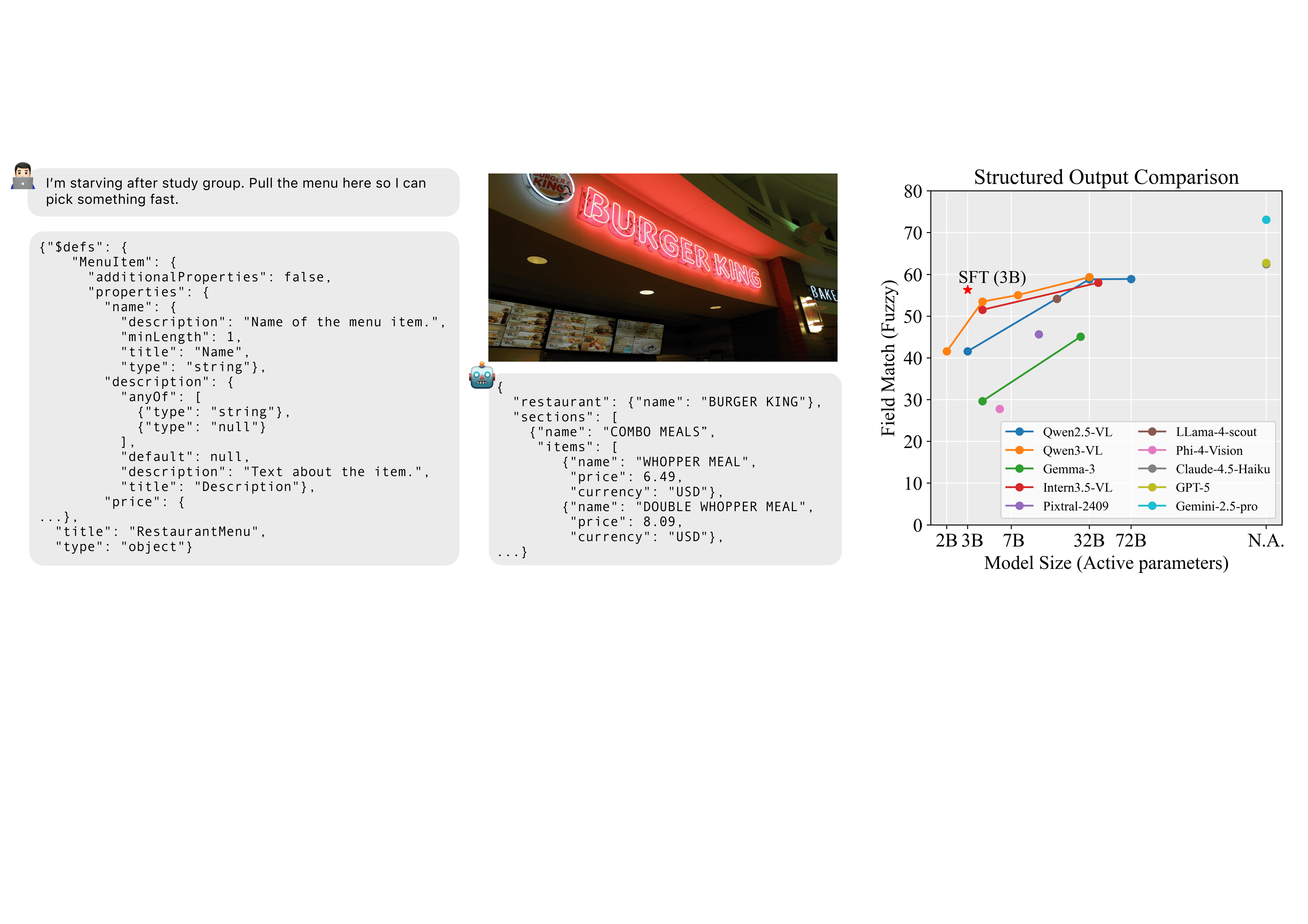
Multimodal large language models (MLLMs) are increasingly deployed in real-world, agentic settings where outputs must not only be correct, but also conform to predefined data schemas. Despite recent progress in structured generation in textual domain, there is still no benchmark that systematically evaluates schema-grounded information extraction and reasoning over visual inputs. In this work, we conduct a comprehensive study of visual structural output capabilities for MLLMs with our carefully designed SO-Bench benchmark. Covering four visual domains, including UI screens, natural images, documents, and charts, SO-Bench is built from over 6.5K diverse JSON schemas and 1.8K curated image-schema pairs with human-verified quality. Benchmarking experiments on open-sourced and frontier proprietary models reveal persistent gaps in predicting accurate, schema compliant outputs, highlighting the need for better multimodal structured reasoning. Beyond benchmarking, we further conduct training experiments to largely improve the model’s structured output capability. We plan to make the benchmark available to the community.
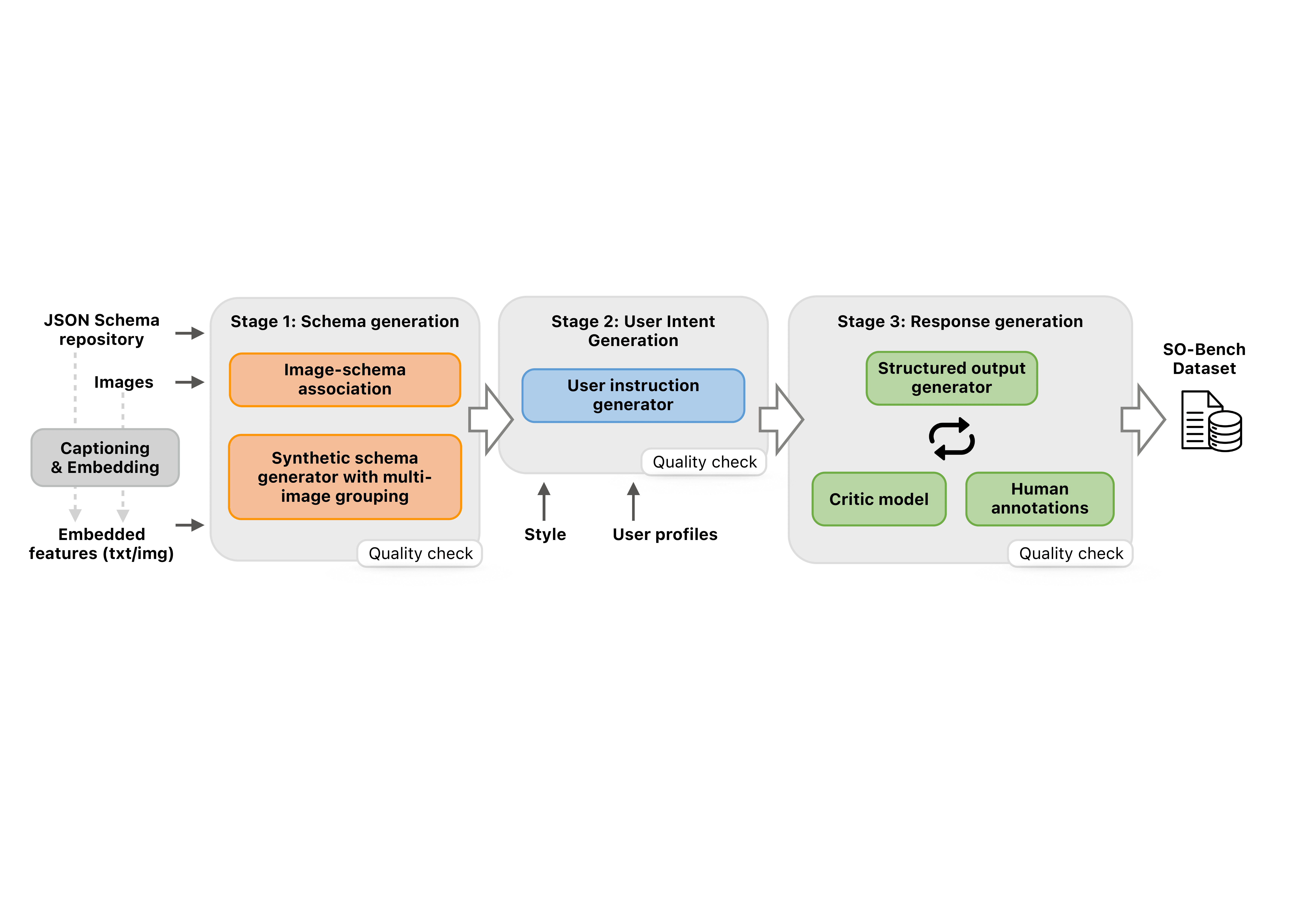
Figure 1: Left: Overview of the multi-stage data generation pipeline for SO-Bench, including schema generation, user intent generation, and response generation stages. At each stage, proprietary frontier models such as GPT-5 and Gemini-2.5-Pro act as generators with carefully designed prompts. Human domain experts review data from each stage before it progresses to the next. Prior to schema generation, input images and JSON schemas are embedded using a CLIP model for embedding search. Right: Benchmarking results among several open-source models and proprietary frontier models.
Figure 2: Overview of the multi-stage data generation pipeline for SO-Bench, including schema generation, user intent generation, and response generation stages. At each stage, proprietary frontier models such as GPT-5 and Gemini-2.5-Pro act as generators with carefully designed prompts. Human domain experts review data from each stage before it progresses to the next. Prior to schema generation, input images and JSON schemas are embedded using a CLIP model for embedding search.
We introduce MIA-Bench, a new benchmark designed to evaluate multimodal large language models (MLLMs) on their ability to strictly adhere to complex instructions. Our benchmark comprises a diverse set of 400 image-prompt pairs, each crafted to challenge the models’ compliance with layered instructions in generating accurate responses that satisfy specific requested patterns. Evaluation results from a wide array of state-of-the-art MLLMs reveal…
We introduce MIA-Bench, a new benchmark designed to evaluate multimodal large language models (MLLMs) on their ability to strictly adhere to complex instructions. Our benchmark comprises a diverse set of 400 image-prompt pairs, each crafted to challenge the models’ compliance with layered instructions in generating accurate responses that satisfy specific requested patterns. Evaluation results from a wide array of state-of-the-art MLLMs reveal…