content type paperpublished December 2025
Semantic Regexes: Auto-Interpreting LLM Features with a Structured Language
AuthorsAngie Boggust†, Donghao Ren, Yannick Assogba, Dominik Moritz, Arvind Satyanarayan†, Fred Hohman
Semantic Regexes: Auto-Interpreting LLM Features with a Structured Language
AuthorsAngie Boggust†, Donghao Ren, Yannick Assogba, Dominik Moritz, Arvind Satyanarayan†, Fred Hohman
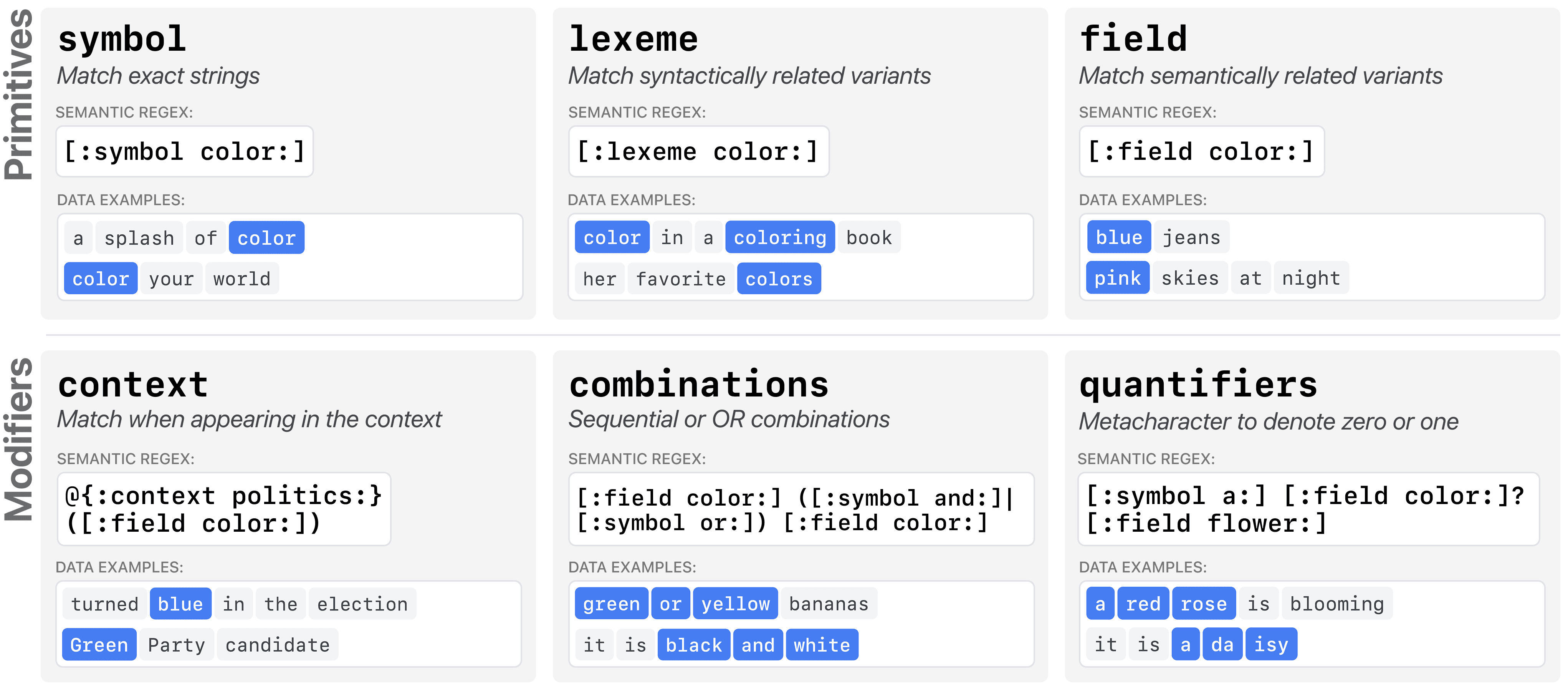
Automated interpretability aims to translate large language model (LLM) features into human understandable descriptions. However, these natural language feature descriptions are often vague, inconsistent, and require manual relabeling. In response, we introduce semantic regexes, structured language descriptions of LLM features. By combining primitives that capture linguistic and semantic feature patterns with modifiers for contextualization, composition, and quantification, semantic regexes produce precise and expressive feature descriptions. Across quantitative benchmarks and qualitative analyses, we find that semantic regexes match the accuracy of natural language while yielding more concise and consistent feature descriptions. Moreover, their inherent structure affords new types of analyses, including quantifying feature complexity across layers, scaling automated interpretability from insights into individual features to model-wide patterns. Finally, in user studies, we find that semantic regex descriptions help people build accurate mental models of LLM feature activations.
Text-Conditional JEPA for Learning Semantically Rich Visual Representations
May 7, 2026research area Computer Vision, research area Methods and Algorithmsconference ICML
Image-based Joint-Embedding Predictive Architecture (I-JEPA) offers a promising approach to visual self-supervised learning through masked feature prediction. However with the inherent visual uncertainty at masked positions, feature prediction remains challenging and may fail to learn semantic representations. In this work, we propose Text-Conditional JEPA (TC-JEPA) that uses image captions to reduce the prediction uncertainty. Specifically, we…
Rescribe: Authoring and Automatically Editing Audio Descriptions
October 8, 2020research area Accessibility, research area Human-Computer Interactionconference UIST
Audio descriptions make videos accessible to those who cannot see them by describing visual content in audio. Producing audio descriptions is challenging due to the synchronous nature of the audio description that must fit into gaps of other video content. An experienced audio description author will produce content that fits narration necessary to understand, enjoy, or experience the video content into the time available. This can be especially…

Our research in machine learning breaks new ground every day.