content type paperpublished June 2025
Scaling Laws for Forgetting During Finetuning with Pretraining Data Injection
AuthorsLouis Béthune, David Grangier, Dan Busbridge, Eleonora Gualdoni, Marco Cuturi, Pierre Ablin
Scaling Laws for Forgetting During Finetuning with Pretraining Data Injection
AuthorsLouis Béthune, David Grangier, Dan Busbridge, Eleonora Gualdoni, Marco Cuturi, Pierre Ablin
A widespread strategy for obtaining a language model that performs well in a target domain is to fine-tune it by training it to do unsupervised next-token prediction on data from that domain. Fine-tuning presents two challenges: i) if the amount of target data is limited, as is the case in most practical applications, the model will quickly overfit, and ii) the model will drift away from the original model and forget the pre-training distribution. This paper quantifies these two phenomena for several target domains, available target data, and model scales. We also measure the efficiency of mixing pre-training and target data for fine-tuning to avoid forgetting and mitigate overfitting. A key practical takeaway from our study is that including as little as 1% of pre-training data in the fine-tuning data mixture shields the model from forgetting the pre-training set.
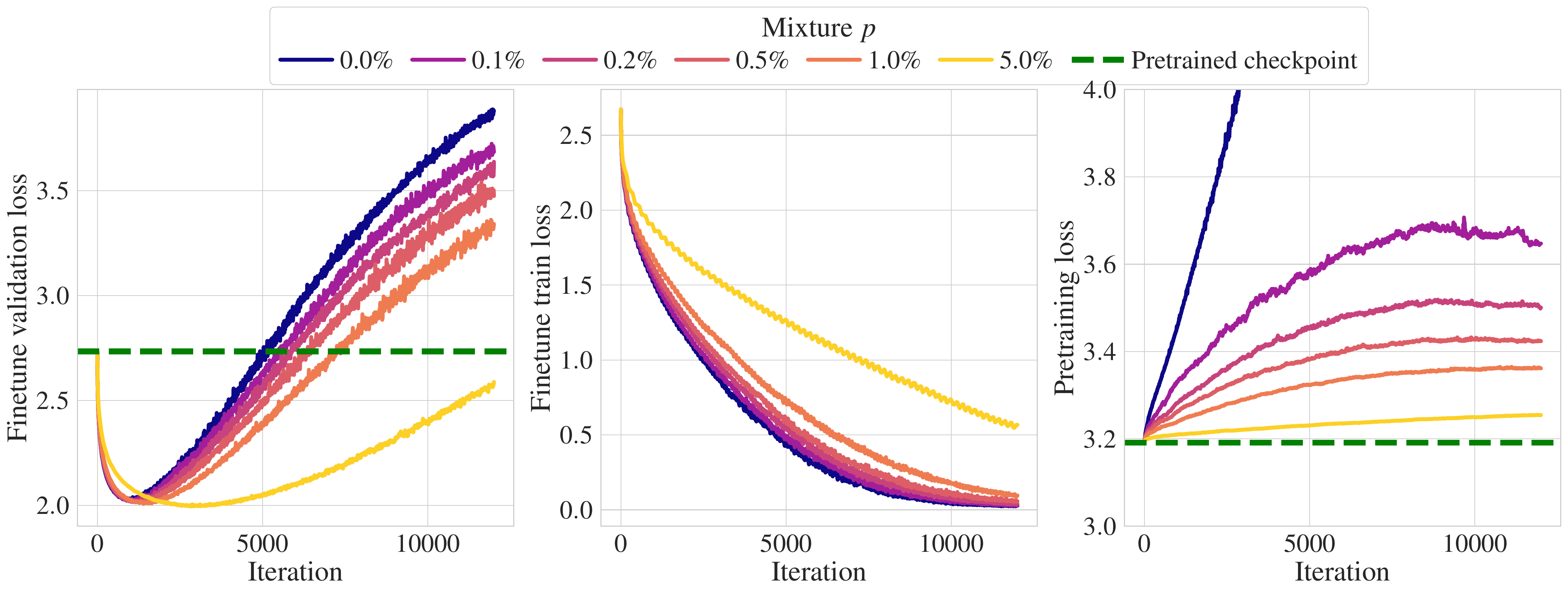
Figure 1: As little as 1% of pre-training data is sufficient to shield against forgetting.
DynaMiCS: Fine-Tuning LLMs with Performance Constraints Using Dynamic Mixtures
July 7, 2026research area Methods and Algorithms, research area Speech and Natural Language Processing
Multi-domain fine-tuning of large language models requires improving performance on target domains while preserving performance on constrained domains, such as general knowledge, instruction following, or safety evaluations. Existing data mixing strategies rely on fixed heuristics or adaptive rules that cannot explicitly enforce preservation of such capabilities. We propose DynaMiCS, a dynamic mixture optimizer that casts multi-domain fine-tuning…
Apple Machine Learning Research at ICML 2025
July 11, 2025
Apple researchers are advancing AI and ML through fundamental research, and to support the broader research community and help accelerate progress in this field, we share much of this research through publications and engagement at conferences. Next week, the International Conference on Machine Learning (ICML) will be held in Vancouver, Canada, and Apple is proud to once again participate in this important event for the…

Our research in machine learning breaks new ground every day.