content type paperpublished May 2026
RVPO: Risk-Sensitive Alignment via Variance Regularization
AuthorsIvan Montero, Tomasz Jurczyk, Bhuwan Dhingra
RVPO: Risk-Sensitive Alignment via Variance Regularization
AuthorsIvan Montero, Tomasz Jurczyk, Bhuwan Dhingra
Current critic-less RLHF methods aggregate multi-objective rewards via an arithmetic mean, leaving them vulnerable to constraint neglect: high-magnitude success in one objective can numerically offset critical failures in others (e.g., safety or formatting), masking low-performing “bottleneck” rewards vital for reliable multi-objective alignment. We propose Reward-Variance Policy Optimization (RVPO), a risk-sensitive framework that penalizes inter-reward variance during advantage aggregation, shifting the objective from “maximize sum” to “maximize consistency.” We show via Taylor expansion that a LogSumExp (SoftMin) operator effectively acts as a smooth variance penalty. We evaluate RVPO on rubric-based medical and scientific reasoning with up to 17 concurrent LLM-judged reward signals (Qwen2.5-3B/7B/14B) and on tool-calling with rule-based constraints (Qwen2.5-1.5B/3B). By preventing the model from neglecting difficult constraints to exploit easier objectives, RVPO improves overall scores on HealthBench (0.261 vs. 0.215 for GDPO at 14B, p < 0.001) and maintains competitive accuracy on GPQA-Diamond without the late-stage degradation observed in other multi-reward methods, demonstrating that variance regularization mitigates constraint neglect across model scales without sacrificing general capabilities.
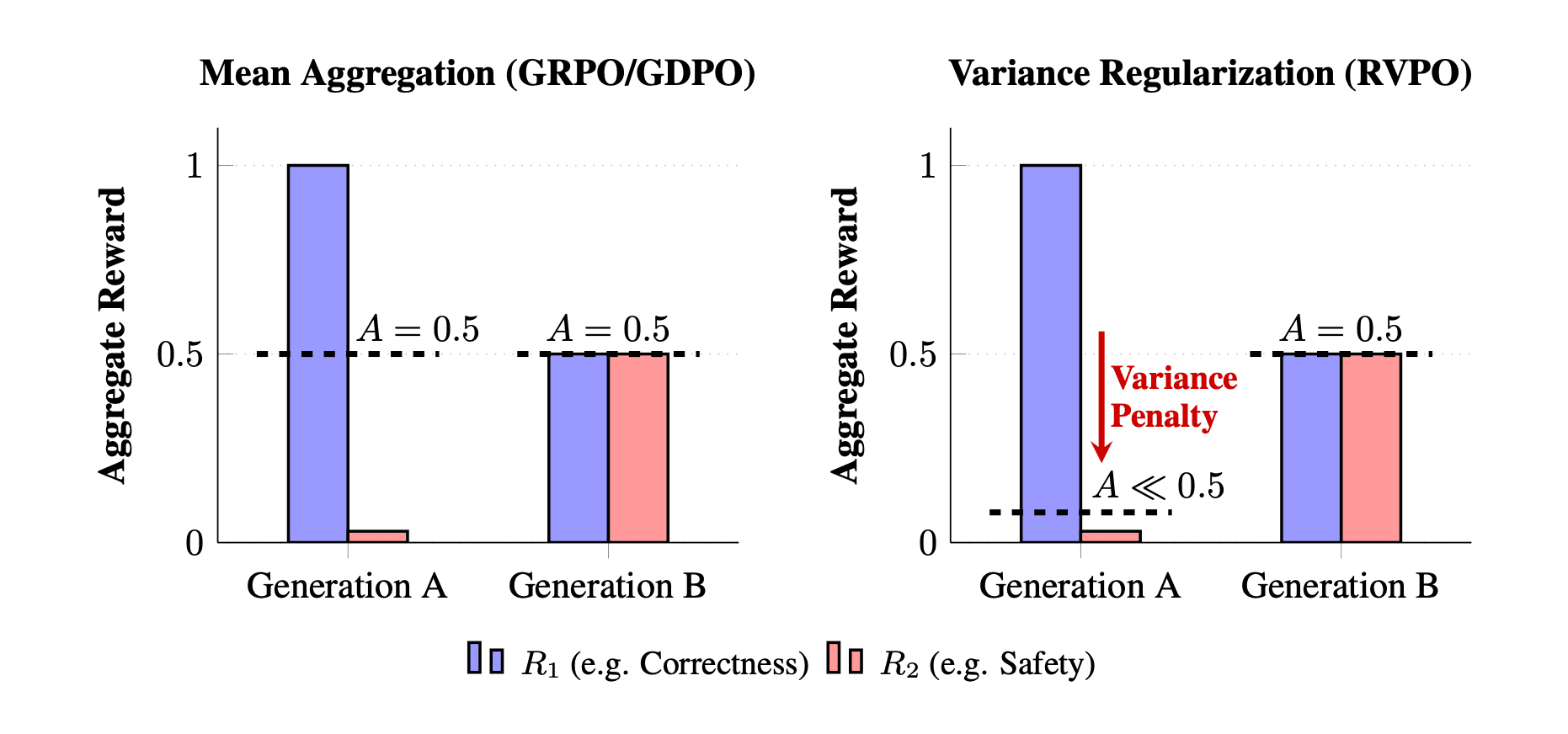
Figure 1: Constraint Neglect in Multi-Objective RLHF. (Left) Mean aggregation (GRPO/GDPO) treats outputs with critical constraint failures (Gen A) as mathematically identical to balanced outputs (Gen B), blinding the optimizer to critical failures. (Right) RVPO applies a soft-min operator to penalize inter-reward variance, heavily discounting Gen A to enforce bottleneck constraints.
On the Limited Generalization Capability of the Implicit Reward Model Induced by Direct Preference Optimization
October 9, 2024research area Methods and Algorithms, research area Speech and Natural Language Processingconference EMNLP
Reinforcement Learning from Human Feedback (RLHF) is an effective approach for aligning language models to human preferences. Central to RLHF is learning a reward function for scoring human preferences. Two main approaches for learning a reward model are 1) training an explicit reward model as in RLHF, and 2) using an implicit reward learned from preference data through methods such as Direct Preference Optimization (DPO). Prior work has shown…
Only Pay for What Is Uncertain: Variance-Adaptive Thompson Sampling
May 3, 2024research area Data Science and Annotation, research area Methods and Algorithmsconference ICLR
Most bandit algorithms assume that the reward variances or their upper bounds are known, and that they are the same for all arms. This naturally leads to suboptimal performance and higher regret due to variance overestimation. On the other hand, underestimated reward variances may lead to linear regret due to committing early to a suboptimal arm. This motivated prior works on variance-adaptive frequentist algorithms, which have strong…

Our research in machine learning breaks new ground every day.