Video 1: The iPhone user captures elements of a kitchen. RoomPlan scans walls, doors, windows, appliances, and storage elements to render a 3D room representation.
Video 1: The iPhone user captures elements of a kitchen. RoomPlan scans walls, doors, windows, appliances, and storage elements to render a 3D room representation.
3D Scene understanding has been an active area of machine learning (ML) research for more than a decade. More recently the release of LiDAR sensor functionality in Apple iPhone and iPad has begun a new era in scene understanding for the computer vision and developer communities. Fundamental research in scene understanding combined with the advances in ML can now impact everyday experiences. A variety of methods are addressing different parts of the challenge, like depth estimation, 3D reconstruction, instance segmentation, object detection, and more. Among these problems, creating a 3D floor plan is becoming key for many applications in augmented reality, robotics, e-commerce, games, and real estate.
To address automatic 3D floor-plan generation, Apple released RoomPlan in 2022. Powered by ARKit and RealityKit software frameworks for developing augmented reality games and applications, RoomPlan is a new Swift API that uses the camera and LiDAR Scanner on iPhone and iPad to create a 3D floor plan of a room, including dimensions and types of furniture. Easy-to-understand prompts guide the user to better capture (or scan) planes and objects in the room at the right speed, lighting, and distance. The resulting room capture is provided as a parametric representation and can be exported to various Universal Scene Description (USD) formats, including USD, USDA, or USDZ.
At the heart of RoomPlan are two main components:
3D room layout estimation
3D object-detection pipeline
An example of the scanning process from an iPhone user’s point of view for a kitchen is shown in Video 1.
The 3D room layout estimator leverages two neural networks, one that detects walls and openings, and another that detects doors and windows. The estimator detects walls and openings as lines and lifts them into 3D using estimated wall height. It detects doors and windows on 2D wall planes and later projects them into 3D space, given the wall information and camera position.
The 3D object-detection pipeline recognizes 16 object categories directly in 3D, covering major room-defining furniture types, such as sofa, table, and refrigerator. In this article, we cover these two main 3D components in more detail.
A fundamental component of RoomPlan is room layout estimation (RLE). RLE detects walls, openings, doors, and windows, then processes the data on the user’s iPhone or iPad in real time, as the device camera scans the environment. This task is inherently challenging due to factors such as variations in room size, furniture that might block structures or openings (furniture occlusion), as well as the presence of plate glass and mirrored walls.
To tackle these challenges, we designed a pipeline that we describe in detail below. The pipeline consists of two main neural networks: One is in charge of detecting walls and openings, and the other is responsible for detecting doors and windows.
As shown in Figure 1, we have designed a two-stage algorithm. In the first stage, we use a neural network that takes the point clouds along with their semantic labels (for simplicity, we will call this semantic point clouds throughout this article) and predicts the 2D walls and openings in a bird’s-eye view of the scene. In the second stage, the detected 2D walls and openings are lifted into 3D using a series of postprocessing algorithms that leverage the wall height.
Room Layout Estimation
Walls and Openings
Figure 1: The figure shows the room layout estimation (RLE) process, starting with the walls and openings pipeline. RoomPlan predicts the walls and openings as 2D lines via our end-to-end line detector neural network. The lines are then lifted to 3D using our postprocessing pipeline, which leverages the estimated wall height.
Our wall and openings detection pipeline first converts the input semantic point clouds to two pseudo-image representations:
Semantic map
Z-slicing map
The semantic map is an HxWxK vector that encodes the semantic information of the space from the bird’s-eye view, where H, W, and K are image length, width, and number of semantic classes respectively. This input is created by projecting every point cloud and its associated semantic vector to a 2D bird’s-eye view of the image grid.
For z-slicing, we map the points into an HxWxZ voxel space, where Z is the number of slices along the gravity direction. Each voxel is a float number between 0 and 1, and each represents the density of point clouds that fall within that voxel. More specifically, we chose H, W, and Z to be 512, 512, and 12 respectively. For voxel resolution, we chose 3 cm along the x and y axes and 30 cm along the z axis. This design allows us to support rooms with a maximum size of 15 m by 15 m and maximum height of up to 3.6 m, while maintaining the balance between speed and measurement accuracy.
Inspired by end-to-end wireframe parsing, we use an end-to-end trainable line-detection network to predict 2D room layouts in bird’s-eye view. The network takes as input the concatenation of the z-slicing map along with the semantic map, and feeds them through a U-Net backbone with 2D-depth separable convolutions. The output of the network consists of a corner map and an edge map of walls and openings. The corner map identifies which pixels in a bird’s-eye view of a room belong to a corner of a wall or an opening. Consequently, the edge map identifies the likelihood of each pixel belonging to a wall or an opening. Once corners are detected, the line-sampler modules enumerate the pairs of corners to generate a line proposal. At the end, a line-verification network is applied to the proposals to do final classifications.
Our wall and opening detection pipeline, not only enables us to scan large rooms of up to 15 m by 15 m but also to produce highly accurate measurements. Additionally, the pipeline runs in real time on the iPhone and iPad, and it is capable of accounting for wall occlusions, small structures, and reflections from glass and mirrored walls.
Doors and Windows
Figure 2: We formulate the problem as 2D detection. The wall information is used to project the input into wall planes. This is later fed to our neural network, called the 2D orthographic detector, that predicts the location of the doors and windows in 2D planes. This output is later lifted into 3D along with the wall and camera information.
Another important component of the RLE pipeline is the detection of doors and windows. Doors and windows are mostly rectangular planar objects on the wall. To reduce the impact of the user’s viewpoints and angles, we adopt an orthographic-detection approach, as shown in Figure 2. The goal is to detect the planar surfaces representing doors and windows on each wall.
This approach has three major highlights:
It can detect doors and windows in real time during a live scan.
It can support different status of the doors. For example, it can distinguish a closed door from an open door.
It is fully supported on the Apple Neural Engine (ANE).
We start by generating projection maps for each wall, which is provided by our wall and opening detection pipeline. Our projection maps consist of a semantic map, an RGB map, and a point-distance map, which are generated by projecting the semantic, RGB, and distance of each point cloud to its nearest wall. The input is then fed to our 2D orthographic detector, which is built on the commonly used single-shot 2D object detectors. To achieve the power and latency needed to run our model on iPhone and iPad, we adopted a backbone similar to EfficientNet architecture.
Similar to the semantic map generated from the walls and openings module, our semantic map for doors and windows is an HxWxK vector that encodes the semantic information of the space from the orthographic view, where K=10, to balance the need for power and performance. The RGB map, which is generated by an RGB point cloud, follows the same projection method and then forms an HxWx3 vector. Last but not least, the distance map encodes the normalized nearest distance between points and nearby walls. This is an HxWx1 vector. Finally, after concatenating the semantic map, RGB map, and distance map, our orthographic detector has the customized input of 14 channels.
To evaluate the proposed detector, we conducted experiments on scans of thousands of rooms from around the world. We achieved 95 percent precision and recall for the wall and window category and 90 precent for the door category. The precision and recall are calculated based on the matching condition on 2D box intersection over union (IOU) between prediction and ground truth.
The second major component of 3D parametric rooms generated by RoomPlan is our 3D object-detection (3DOD) pipeline. This pipeline is in charge of detecting 16 object categories, including:
Furniture, such as sofa and table
Appliances, such as washer and refrigerator
Other room-defining elements, such as bathtub and sink
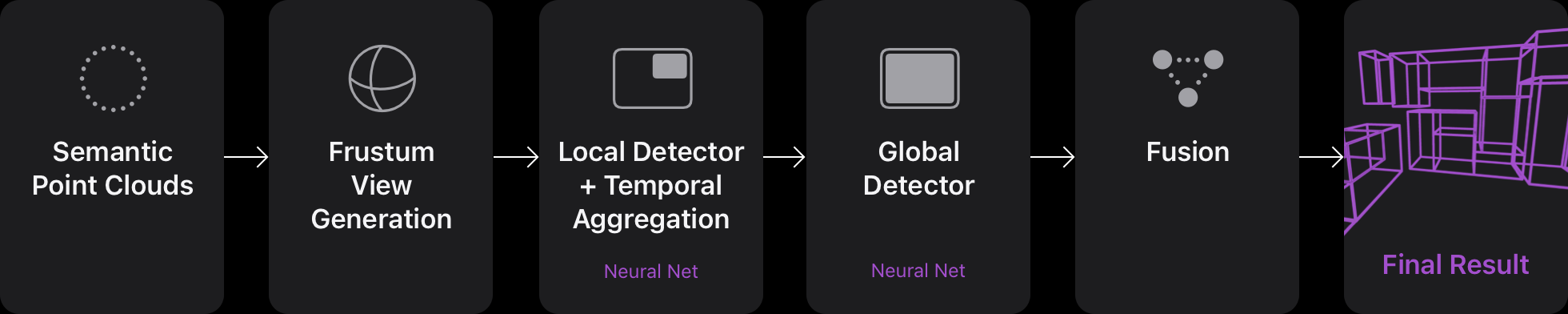
Our 3DOD pipeline consists of a local detector, a global detector, and a fusion algorithm, as seen in Figure 3. First, given a series of RGB-D frames along with their camera poses, we generate a wide frustum view from the accumulated semantic point clouds. This is later fed to our local 3DOD model, which detects the room-defining elements during online scanning. These boxes are aggregated, tracked over time, and visible to the user during the scan. See Video 2 for an example.
Once the user completes the scan, we run our global detector, which instead of a frustum takes the whole reconstructed scene as input and predicts bounding boxes. The global 3DOD model is trained on only a subset of the categories, which includes larger items of furniture, such as cabinet and table. By using a global detector, we can gather contextual information about larger objects, information that might be missing from the small camera frustum view during online scanning. Lastly, the input of the local and global detectors, along with the wall information obtained from RLE, are fed to our fusion pipeline, which generates the final output. The fusion pipeline not only combines the results of local and global detectors but also makes positional adjustments to predictions, given the wall locations. For example, we make sure that bounding boxes don’t cut through the walls.
Figure 3: We create a wider frustum view by accumulating semantic point clouds. The local detector detects the oriented bounding boxes in a frustum, and aggregates them. Global detection then works with scene contextual information to detect large furniture. The accumulated results and boxes are combined to generate the final output.
Our local and global detectors follow very similar architecture except for the input data and the categories that they are trained on. The input frustum to our local detector is 7.2 m x 4.8 m x 3.6 m. We chose a voxel size of 15 cm, which makes our network input size 48 x 32 x 24 voxels. We found that 15 cm provided a good trade-off between accuracy, speed, and memory. The feature dimension for each voxel is 35, which is simply the concatenation of xyz values, normalized z, and semantic features. For backbone, we use a 3D Convolution U-Net architecture that includes three downsampling and three upsampling layers.
Using the following steps, the network predicts the objectness score, center, type, size, and orientation at each voxel:
To output the objectness score, we use two channels, identifying whether an object is present or not present at each voxel.
To output the object center, we use three channels, indicating the xyz offset from the voxel center.
To output the object type, we use N channels, which equals the number of supported categories.
To output the object size, we have size templates (S), and we predict a classification score for each size template, as well as three scale-regression offsets for height, width, and length. The size channel is 4xS.
To output the object orientation, we divide the orientation angle into multiple bins (H), and predict a classification score and a regression offset for each bin, relative to the bin center and normalized by the bin size. The orientation channel is 2xH.
In local detection, the total number of channels is 2+3+2H+4S+N, where N=16, H=12, and S=16. The taxonomy categories of the local detector include storage, sofa, table, chair, bed, refrigerator, oven, stove, dishwasher, washer or dryer, fireplace, sink, bathtub, toilet, stairs, and TV.
Video 2: The video depicts RoomPlan's qualitative results. It includes a variety of furniture, such as a TV, sofa, and refrigerator, as well as different types of doors and windows. Each object category is shown with a different color.
In global detection, N=S=4. The supported categories are large pieces of furniture, including storage, sofa, table, and bed.
The last component of 3DOD is box fusion, which is critical for generating the final dollhouse result (that is, the 3D representation of the whole room). Box fusion starts with the accumulated boxes from the local detector and slightly modifies them by leveraging the global-detection result. For example, the global detector might detect a set of connected kitchen cabinets as one object, which guides the fusion algorithm to better align or connect the built-in kitchen appliance with the cabinets. The fusion logic also looks into pair relationships between multiple objects, such as forming two detected sofa boxes into an L-shaped sofa by clipping the two sofa boxes to exactly 90 degrees. Last but not least, the fusion step calculates the relationship between object and wall. The fusion process clips or aligns the object to the nearby walls, and makes sure the objects are not intersecting with any wall.
We evaluated the 3DOD pipeline on the same rooms on which we evaluated the floor plan and windows and doors. At a 3D intersection over union (IOU) of 30 percent, the average precision and recall across 16 categories are 91 percent and 90 percent respectively. The eight categories of refrigerator, stove, bed, sink, toilet, bath, sofa, and washer or dryer have both precision and recall greater than 93 percent. The most difficult category is chair, with 83 percent precision and 87 percent recall, which is mainly due to heavy occlusion or crowded arrangement.
As we explained above, RoomPlan uses semantic point clouds as the input to its two major components, RLE and 3D Object Detection. The quality of semantic point clouds depends heavily on the quality of the depth estimation algorithm, the semantic segmentation model, and the SLAM pipeline. Several factors can impact our input quality, including scan pattern and lighting. In order to ensure that our algorithms receive high-quality input, RoomPlan provides real-time feedback to the user, with text instructions to adjust the lighting, scanning speed, and distance from the wall. To achieve this we designed several models that detect such conditions. As soon as RoomPlan detects one of these conditions, the user receives a notification, such as “Turn up the light,” “Slow down,” or “Move farther away.”
The detection algorithms take ARFrame class images provided by ARKit as input. We train separate models to detect different scan conditions. These models take different features as input. For light conditions, we take the average luminance of the image as an input feature as well as ARFrame raw feature points. If we take only the luminance of image values as input, the result might mistakenly identify a dark object (for example, a cabinet painted black) as a low-light condition. Using 3D key feature points provides additional context. For distance and speed conditions, we compute the 3D linear velocity of camera-pose transitions and 2D projection velocity in image space. Combining these two features, we encode camera movement (rotation and transition) as well as the distance of the camera to elements detected during scanning. The detection networks are two-layer multiple-layers perceptron (MLP) with only dozens of parameters. Simple as these models are, we achieved 90 percent accuracy across all three detection tasks.
Each home, whether a house, apartment, or other dwelling, has its own unique properties, specifically when comparing households in different parts of the globe. To ensure our algorithms can accommodate variations in room types, we collected data from a number of homes from many different countries. To further increase the scene diversity and reduce bias in our dataset, we selected homes from rural, suburban, and urban locations from various socioeconomic levels.
Our data collection setup is very similar to the ARKitScenes dataset from Apple. After selecting a home for data collection, we divided each home into multiple scenes (in most cases, each scene covers one room), and performed the following steps.
First, we used a standard high-resolution laser scanner, the Faro Focus S70 stationary laser scanner, on a tripod to collect highly accurate XYZRGB point clouds of the environment. We chose tripod locations to maximize surface coverage, and on average we collected four laser scans per room.
Second, we recorded up to three video sequences, attempting to capture all the surfaces in each room using an iPhone and iPad. Because using different motion patterns helps improve the robustness of our algorithm to different scan patterns, each sequence followed a different motion pattern. We captured the ceiling, floor, walls, and room-defining objects in our scans. While collecting data, we tried to keep the environment completely static and adjusted some environmental aggressors, such as lighting. We labeled all the data in house using our labeling tools. In most cases, we labeled our ground truth on reconstructed scenes.
The end-to-end RoomPlan processing runs entirely on the user’s device, not on Apple servers, in keeping with Apple’s commitment to user privacy. To achieve this goal, all three neural networks explained earlier in this article run entirely on Apple Neural Engine (ANE). We used techniques such as quantization, model pruning, and architecture search to achieve the latency and memory requirements to run RoomPlan smoothly on the device. Our goal was to allow users to scan large rooms without experiencing CPU/GPU thermal throttling, which can cause unexpected behaviors such as frame drops. To this end, we found out that a five-minute scan is long enough to cover a wide range of room sizes, including rooms of up to 15 m x 15 m.
In this article we cover the technical details behind the RoomPlan API, which allows users to create a 3D floor plan of their space. This ability is becoming key for many applications in the domains of augmented reality, robotics, e-commerce, games, and real estate. We cover in depth RoomPlan’s two major components, room layout estimation and 3D object detection. We show how these pipelines can run efficiently in terms of power and latency on both iPhone and iPad.
Many people contributed to this work, including Afshin Dehghan, Yikang Liao, Hongyu Xu, Fengfu Li, Yang Yang, Alex Ke, Max Maung, Kota Hara, Peter Fu, Louis Gong, Yihao Qian, Zhuoyuan Chen, Guangyu Zhao, Tianxin Deng, Shaowei Liu, Chunyuan Cao, Rongqi Chen, Zhenlei Yan, Peiyin Heng, Jimmy Pan, Yinbo Li, Haiming Gang, Praveen Sharma, Antoine Tarault, Daniel Ulbricht, Haris BaigKai Kang, Joerg Liebelt, Peng Wu, and Feng Tang.
Baruch, Gilad, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, and Elad Shulman. “ARKitScenes: A Diverse Real-World Dataset for 3D Indoor Scene Understanding Using Mobile RGB-D Data.” January 2022. [link.]
Gwak, JunYoung, Christopher Choy, and Silvio Savarese. “Generative Sparse Detection Networks for 3D Single-shot Object Detection.” June 2020. [link.]
Liu, Wei, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C. Berg. “SSD: Single Shot MultiBox Detector.” December 2016. [link.]
Tan, Mingxing, and Quoc V. Le. “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”. September 2020. [link.]
Zhou, Yichao, Haozhi Qi, and Yi Ma. “End-to-End Wireframe Parsing.” May 2021. [link.]
We revisit scene-level 3D object detection as the output of an object-centric framework capable of both localization and mapping using 3D oriented boxes as the underlying geometric primitive. While existing 3D object detection approaches operate globally and implicitly rely on the a priori existence of metric camera poses, our method, Rooms from Motion (RfM) operates on a collection of un-posed images. By replacing the standard 2D keypoint-based…
Accurate detection of objects in 3D point clouds is a central problem in many applications, such as autonomous navigation, housekeeping robots, and augmented/virtual reality. To interface a highly sparse LiDAR point cloud with a region proposal network (RPN), most existing efforts have focused on hand-crafted feature representations, for example, a bird’s eye view projection. In this work, we remove the need of manual feature engineering for 3D…