content type highlightpublished August 9, 2018
Finding Local Destinations with Siri’s Regionally Specific Language Models for Speech Recognition
AuthorsSiri Speech Recognition Team
Finding Local Destinations with Siri’s Regionally Specific Language Models for Speech Recognition
AuthorsSiri Speech Recognition Team
The accuracy of automatic speech recognition (ASR) systems has improved phenomenally over recent years, due to the widespread adoption of deep learning techniques. Performance improvements have, however, mainly been made in the recognition of general speech; whereas accurately recognizing named entities, like small local businesses, has remained a performance bottleneck. This article describes how we met that challenge, improving Siri’s ability to recognize names of local POIs by incorporating knowledge of the user’s location into our speech recognition system. Customized language models that take the user’s location into account are known as geolocation-based language models (Geo-LMs). These models enable Siri to better estimate the user’s intended sequence of words by using not only the information provided by the acoustic model and a general LM (like in standard ASR) but also information about the POIs in the user’s surroundings.
Generally, virtual assistants correctly recognize and understand the names of high-profile businesses and chain stores like Starbucks, but have a harder time recognizing the names of the millions of smaller, local POIs that users ask about. In ASR, there’s a known performance bottleneck when it comes to accurately recognizing named entities, like small local businesses, in the long tail of a frequency distribution.
We decided to improve Siri’s ability to recognize names of local POIs by incorporating knowledge of the user’s location into our speech recognition system.
ASR systems generally comprise two major components:
We can identify two factors that account for this difficulty:
The second factor causes the word sequences that make up local business names to be assigned very low prior probabilities by a general LM. This, in turn, makes the name of a business less likely to be correctly selected by the speech recognizer.
The method we present in this article assumes that users are more likely to search for nearby local POIs with mobile devices than with Macs, for instance, and therefore uses geolocation information from mobile devices to improve POI recognition. This helps us better estimate the user’s intended sequence of words. We’ve been able to significantly improve the accuracy of local POI recognition and understanding by incorporating users’ geolocation information into Siri’s ASR system.
We define a set of geographic regions (geo regions) covering most of the United States, and construct one Geo-LM for each region. When a user makes a request, the system is customized with a Geo-LM based on the user’s current location. If the user is outside of any defined geo regions, or if Siri doesn’t have access to Location Services, the system defaults to a global Geo-LM. The selected Geo-LM is then combined with acoustic models for ASR decoding. Figure 1 shows the overall workflow of the system.
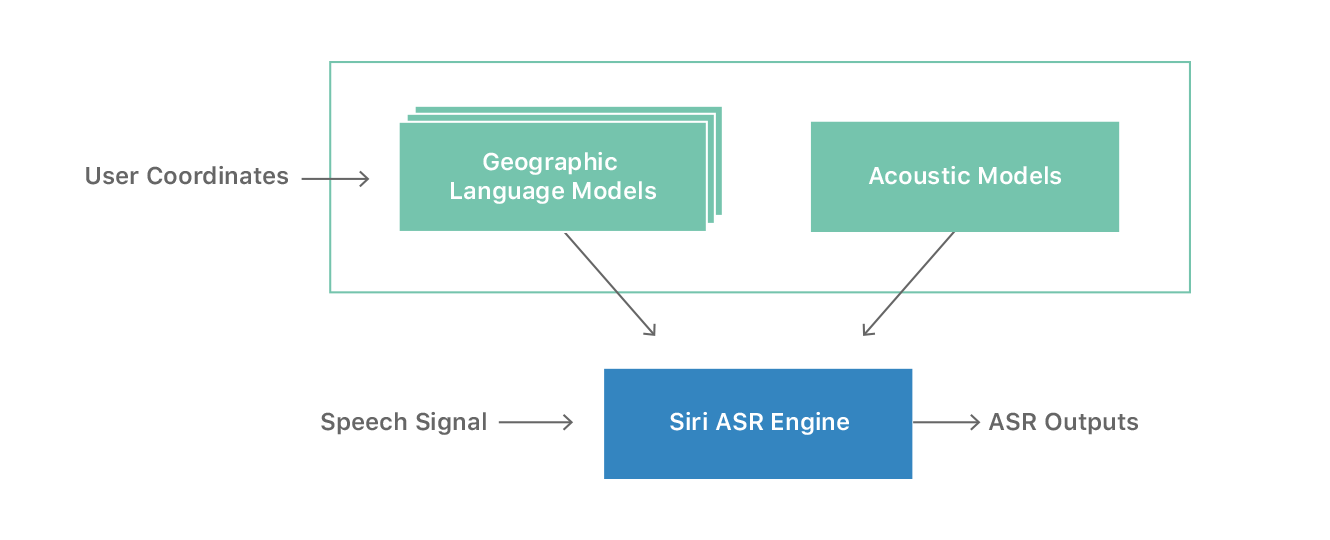
We define geo regions based on the combined statistical areas (CSAs) [1] from U.S. Census Bureau. The CSAs consist of adjacent metropolitan areas that are economically and socially linked, as measured by commuting patterns. There are 169 CSAs covering 80% of the population of the United States. We build a dedicated Geo-LM for each CSA, with a single global Geo-LM to cover all areas not defined by CSA.
To efficiently search the CSA for a user, we store a latitude and longitude lookup table derived from the rasterized cartographic boundary (or shapefile) provided by the U.S. Census Bureau [2]. At runtime, the complexity of geolocation lookup is O(1).
The Siri ASR system uses a weighted finite state transducer (WFST)-based decoder, as first described by Paulik [3]. The decoder employs the difference LM principle, similar to frameworks described in [4,5].
We implement a type of class LM in which we dynamically replace class nonterminals with intraclass grammars. The concept is illustrated in Figure 2. We employ a master LM, which is used for general recognition and includes nonterminal labels for predefined classes, such as geo regions. For each class, a slot LM is built with entity names pertinent to the class and representing intraclass grammars. Geo-LM construction is then conducted with the master LM and the slot LMs as explained in the following section.
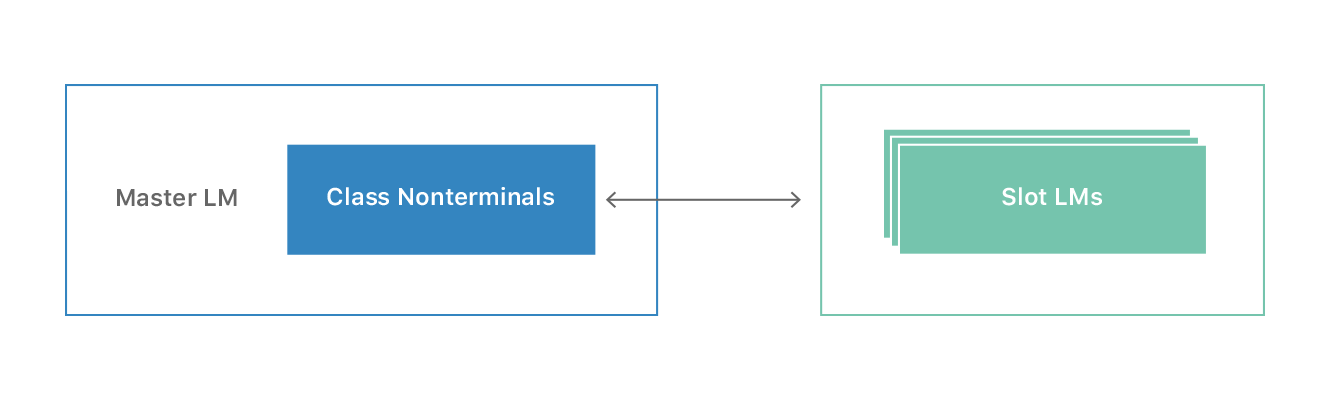
The straightforward way to construct Geo-LM is for each geo region building one LM by interpolating the general LM and the geo-specific LM trained from training text with geo-context. The problem with this approach is that the general LM is usually large because it covers a lot of domains. The cumulative size of the resulting Geo-LMs would be too big to fit in the runtime memory. On the other hand, the POI names can construct compact LMs that can be one-tenth to one-thousandth the size of a full general LM; hence, the proposed class LM framework.
In our class LM framework, the master LM is trained as usual, with training text from all supported domains. To add the support of nonterminal labels, initially we rely on artificially created training text with geo-specific templates, such as “directions to \CS-POI,” where \CS-POI is the class label. This artificial text helps bootstrap the initial recognition of the nonterminals. After Geo-LM deployment, the output from our ASR system would have special markers—for example, \CS-POI—around the Geo entities recognized through the class LM framework. The new Geo-LM output would allow us to continuously supply training text for nonterminals in the master LM.
Slot LM is trained with entities of a specific class—POI, in the case of the Geo-LM. In the proposed system, one slot LM is built for each geo region. The training text for each slot LM consists of the names of local POIs in the corresponding region.
Figure 3 shows a toy example of a WFST-based class LM, including a master LM representing three simple templates with priors (the probability of occurrence of the entry relative to other choices):
*prior=0.5: directions to \CS-POI
*
*prior=0.3: where is \CS-POI
*
prior=0.2: find the nearest \CS-POI
It also includes a slot LM containing only three POIs with priors:
*prior=0.4: Harvard University
*
*prior=0.4: TD Garden
*
prior=0.2: Vidodivino
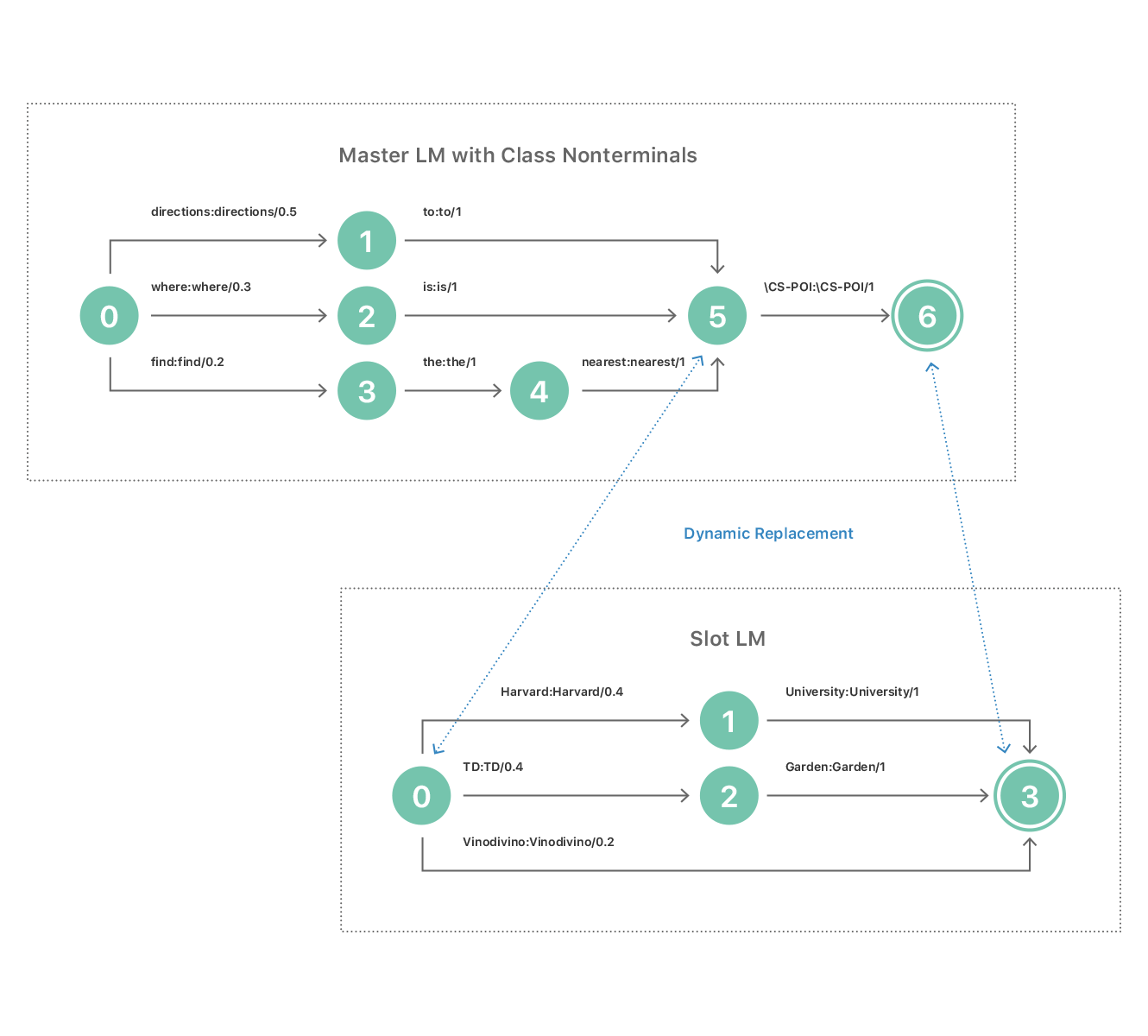
Training POIs as a statistical n-gram LM allows us to model the variations in POI names. For example, both Harvard University and Harvard can be modeled in slot LM as long as Harvard University exists in the training text. We derive priors based on distributions observed in production traffic.
At runtime, it’s essential that we dynamically and efficiently replace the class nonterminals in the master LM with the respective matching slot LM based on the current user location as shown in Figure 3, where \CS-POI represents the class nonterminal in the Geo-LM.
To ensure that the decode lexicon covers all POI names, we employ an in-house grapheme-to-phoneme (G2P) system to derive pronunciations automatically if a word in the POI name isn’t already in our decode lexicon.
This framework allows for flexible updates to the overall system. To update POIs or add new regions, you simply rebuild or add more slot LMs. Rebuilding is quick and efficient because the slot LMs are small. While a typical general LM can be 200 MB or larger, a slot LM is about 0.2 MB to 20 MB, depending on the number of entities included. The flexibility of slot LM updates is essential for the sustainability of our application. This is because of the rapid changes in POIs due to the opening or closing of businesses and their continuously changing popularities. In addition, because slot LMs are small, the proposed framework allows all LMs to be preloaded into system memory during server initialization. Switching slot LMs can thus be done in memory, which results in a very efficient implementation. Based on our measurement, the dynamic combination of master LM and slot LMs introduces only a marginal latency increase.
In this section, we report the benchmark evaluations of the proposed Geo-LM compared to the general LM for the task of POI recognition in the United States. A hybrid convolutional neural network CNN-HMM [6] is used in all experiments. The AM was trained with filter bank features from about 5,000 hours of English speech data. Our Geo-LM is trained as a 4-gram LM. The test data are manually transcribed and labeled with location so that the correct slot LM can be applied during testing. We’ll first describe the data we use for training and testing Geo-LM, and then present the results.
The baseline general LM is trained with the training text (D1) containing a variety of sources of collected, privacy-preserved, live usage data.
The training data for building the master LM in the proposed Geo-LM is composed of D1 and artificially created use-case templates containing the POI class symbol, as described in “Geo-LM Construction.”
To build the slot LMs, we extract the searched POIs from daily updated Apple Maps search logs. The extracted POIs are distributed into 170 groups based on their locations and popularities, to build slot LMs for 169 CSAs and one global group for requests not covered by CSAs. The priors of each POI are set according to their usage frequency in the search logs. Table 1 shows the n-gram size comparison of the general LM against the two components of the Geo-LM. The slot LMs, averaged over 170 regions, are much smaller than the general LM.
| LM type | Number of n-grams (in millions) |
|---|---|
| General LM | 9.3 |
| Geo-LM: | |
| Master | 9.3 |
| 170 slot LMs | 0.7 (average) |
We used two types of test data in our experiments:
Real-world user data randomly selected from Siri production traffic in the United States. We created two test sets from this data:
An internally recorded, local POI search test set (T3). We picked eight major U.S. metropolitan regions and selected the top 1,000 most popular POIs for each region based on Yelp reviews. For each POI, we recorded three utterances, with and without the carrier phrase directions to, from three different speakers. Note that we excluded 6,500 megachains from the list because they’re mostly recognized without Geo-LM and can dominate based on popularity.
We first conducted experiments on the real-world user test sets T1 and T2. The results, summarized in Table 3, show that Geo-LM reduces word error rate (WER) by 18.7% relative on T1, while introducing no degradation in accuracy on T2.
Because T1 is randomly sampled from production traffic, it contains megachains, like Walmart and Home Depot, that the general LM has already recognized. To benchmark the performance of name recognition on more difficult-to-find local POIs, we tested on T3, which doesn’t include megachains. The results, summarized in Table 4, show that while the general LM performs poorly on T3, the proposed Geo-LM universally reduces WER by more than 40% for all eight regions.
We also compared the speed of the two systems and observed that the Geo-LM system increases average latency marginally, by under 10 milliseconds.
| Test set | General LM error (%) | Geo-LM error (%) | Relative error reduction (%) |
|---|---|---|---|
| General (T2) | 6.2 | 6.2 | 0 |
| POI search (T1) | 15.5 | 12.6 | 18.7 |
| Test set region | General LM error(%) | Geo-LM error(%) | Relative error reduction (%) |
|---|---|---|---|
| Boston | 24.3 | 13.7 | 43.6 |
| Chicago | 26.3 | 15.2 | 42.2 |
| Los Angeles | 24.4 | 12.6 | 48.4 |
| Minneapolis | 19.6 | 10.7 | 45.4 |
| New York | 27.3 | 15.7 | 42.5 |
| Philadelphia | 25.8 | 15.0 | 41.9 |
| Seattle | 24.8 | 13.8 | 44.4 |
| San Francisco | 26.5 | 15.1 | 43.0 |
In this work, we present a highly effective Geo-LM framework that provides several benefits:
Our experiments show that using localized information can lead to over 18% WER reduction in local POI search, and more than 40% if excluding megachains.
Because of the limited impact on system speed, regional coverage has more room for improvement and expansion. It is, however, essential to continue providing a global Geo-LM in addition to regional LMs so that ASR can handle long-distance queries and cases with users located outside supported regions.
The method and system proposed here are language independent. As a result, the expansion of Geo-LM support for other locales besides U.S. English is straightforward.
For more details, and for extensive performance evaluation of the Geo-LM that we describe in this article, see our ICASSP 2018 paper, “Geographic Language Models for Automatic Speech Recognition” [7].
[1] U.S. Census Bureau. Combined Statistical Areas of the United States and Puerto Rico. 2015.
[2] U.S. Census Bureau. Cartographic Boundary Shapefiles 2015.
[3] M. Paulik. Improvements to the Pruning Behavior of DNN Acoustic Models Interspeech, 2015.
[4] H. Dolfing and I. Hetherington. Incremental Language Models for Speech Recognition Using Finite-state Transducers. Proceedings of ASRU, 2001, pp. 194–197.
[5] D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz, et al. The Kaldi Speech Recognition Toolkit. Proceedings of ASRU, 2011, pp. 1–4.
[6] O. Abdel-Hamid, A. Mohamed, H. Jiang, L. Deng, G. Penn, and D. Yu. Convolutional Neural Networks for Speech Recognition IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 22, no. 10, pp. 1533-1545, 2014.
[7] X. Xiao, H. Chen, M. Zylak, D. Sosa, S. Desu, M. Krishnamoorthy, D. Liu, M. Paulik, and Y. Zhang. Geographic Language Models for Automatic Speech Recognition. in Proceedings of ICASSP, 2018.
Acoustic Model Fusion for End-to-end Speech Recognition
January 29, 2024research area Speech and Natural Language Processingconference ASRU
Recent advances in deep learning and automatic speech recognition (ASR) have enabled the end-to-end (E2E) ASR system and boosted its accuracy to a new level. The E2E systems implicitly model all conventional ASR components, such as the acoustic model (AM) and the language model (LM), in a single network trained on audio-text pairs. Despite this simpler system architecture, fusing a separate LM, trained exclusively on text corpora, into the E2E…
Error-driven Pruning of Language Models for Virtual Assistants
June 1, 2021research area Speech and Natural Language Processingconference ICASSP
Language models (LMs) for virtual assistants (VAs) are typically trained on large amounts of data, resulting in prohibitively large models which require excessive memory and/or cannot be used to serve user requests in real-time. Entropy pruning results in smaller models but with significant degradation of effectiveness in the tail of the user request distribution. We customize entropy pruning by allowing for a keep list of infrequent n-grams that…

Our research in machine learning breaks new ground every day.