content type paperpublished July 2025
Point-3D LLM: Studying the Impact of Token Structure for 3D Scene Understanding With Large Language Models
AuthorsHugues Thomas, Chen Chen, Jian Zhang
Point-3D LLM: Studying the Impact of Token Structure for 3D Scene Understanding With Large Language Models
AuthorsHugues Thomas, Chen Chen, Jian Zhang
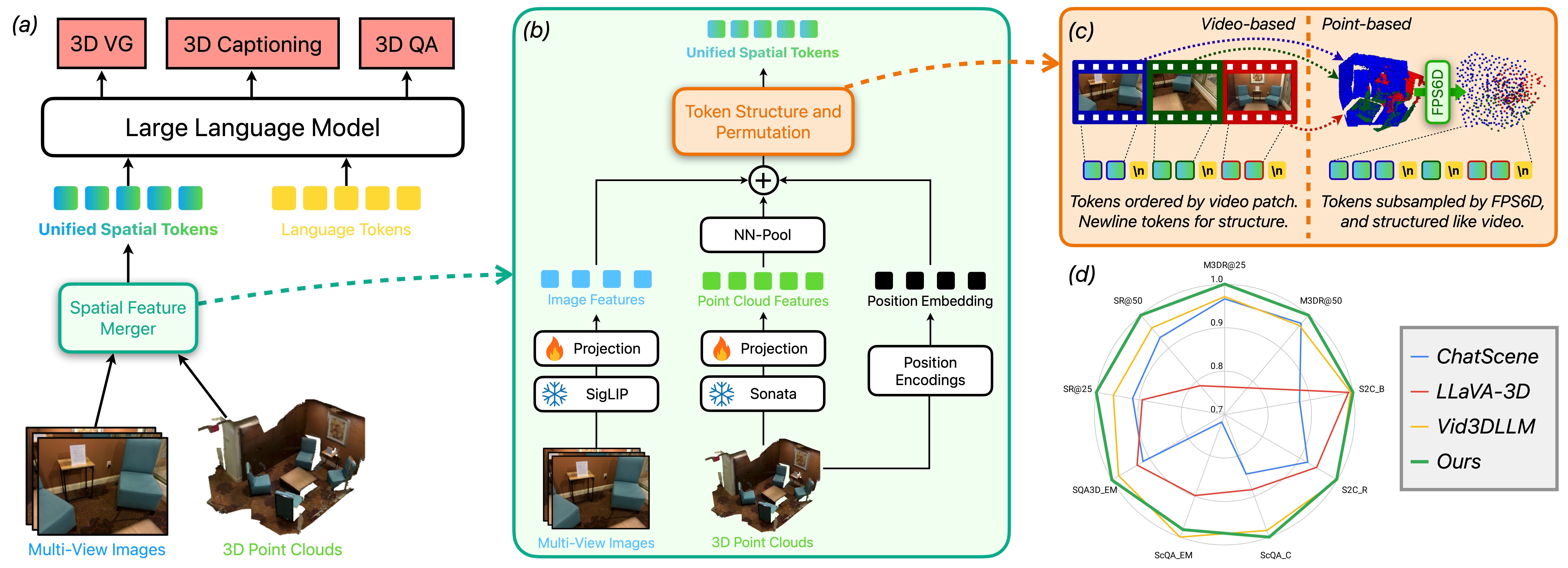
Effectively representing 3D scenes for Multimodal Large Language Models (MLLMs) is crucial yet challenging. Existing approaches commonly only rely on 2D image features and use varied tokenization approaches. This work presents a rigorous study of 3D token structures, systematically comparing video-based and point-based representations while maintaining consistent model backbones and parameters. We propose a novel approach that enriches visual tokens by incorporating 3D point cloud features from a Sonata pretrained Point Transformer V3 encoder. Our experiments demonstrate that merging explicit 3D features significantly boosts performance. Furthermore, we show that point-based token structures can rival video-based ones when the points are cleverly sampled and ordered. Our best models from both structures achieve state-of-the-art results on multiple 3D understanding benchmarks. We emphasize our analysis of token structures as a key contribution, alongside transparent reporting of results averaged over multiple seeds, a practice we believe is vital for robust progress in the field.
VideoFlexTok: Flexible-Length Coarse-to-Fine Video Tokenization
July 2, 2026research area Computer Visionconference ICML
Visual tokenizers map high-dimensional raw pixels into a compressed representation for downstream modeling. Beyond compression, tokenizers dictate what information is preserved and how it is organized. A de facto standard approach to video tokenization is to represent a video as a spatiotemporal 3D grid of tokens, each capturing the corresponding local information in the original signal. This requires the downstream model that consumes the…
(1D) Ordered Tokens Enable Efficient Test-Time Search
July 2, 2026research area Computer Visionconference ICML
Tokenization is a key component of autoregressive (AR) generative models, converting raw data into more manageable units for modeling. Commonly, tokens describe local information, such as regions of pixels in images or word pieces in text, and AR generation predicts these tokens in a fixed order. A worthwhile question is whether token structures affect the ability to steer the generation through test-time search, where multiple candidate…

Our research in machine learning breaks new ground every day.