content type paperpublished June 2025
Instruction-Following Pruning for Large Language Models
AuthorsBairu Hou†**, Qibin Chen, Jianyu Wang, Guoli Yin, Chong Wang, Nan Du, Ruoming Pang, Shiyu Chang†, Tao Lei
Instruction-Following Pruning for Large Language Models
AuthorsBairu Hou†**, Qibin Chen, Jianyu Wang, Guoli Yin, Chong Wang, Nan Du, Ruoming Pang, Shiyu Chang†, Tao Lei
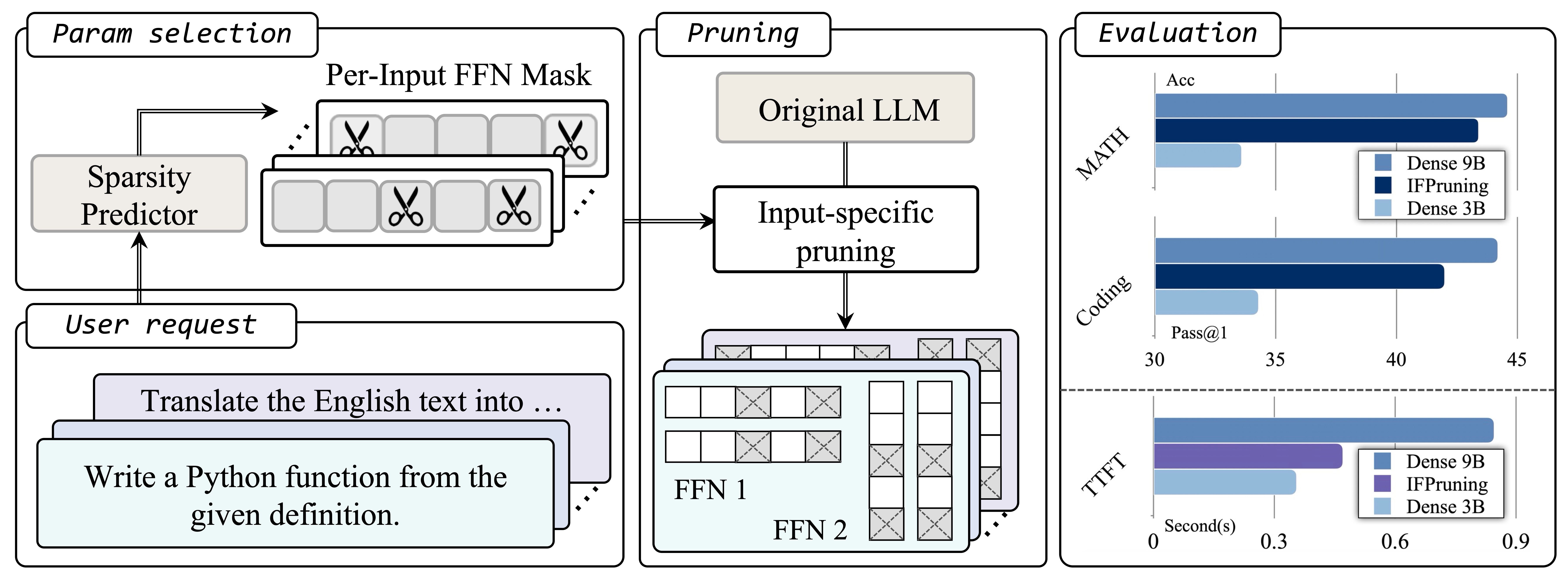
With the rapid scaling of large language models (LLMs), structured pruning has become a widely used technique to learn efficient, smaller models from larger ones, delivering superior performance compared to training similarly sized models from scratch. In this paper, we move beyond the traditional static pruning approach of determining a fixed pruning mask for a model, and propose a dynamic approach to structured pruning. In our method, the pruning mask is input-dependent and adapts dynamically based on the information described in a user instruction. Our approach, termed “instruction-following pruning”, introduces a sparse mask predictor that takes the user instruction as input and dynamically selects the most relevant model parameters for the given task. To identify and activate effective parameters, we jointly optimize the sparse mask predictor and the LLM, leveraging both instruction-following data and the pre-training corpus. Our method shares the same spirit as Mixture-of-Experts (MoE) by dynamically activating a subset of parameters, but is designed to work well for on-device inference. Specifically, by selecting and fixing the parameters for each user-specified task, our method significantly reduces the weight loading cost and makes decoding as efficient as a small-scale dense model. Experimental results confirm the effectiveness of our approach on a wide range of evaluation benchmarks. For example, our 3B activated model improves over the 3B dense model by 5-8 points of absolute margin on domains such as math and coding, and rivals the performance of a 9B model. It also significantly improves the inference efficiency of the 9B model and MoE with a similar number of activated parameters.
Modern neural networks are growing not only in size and complexity but also in inference time. One of the most effective compression techniques — channel pruning — combats this trend by removing channels from convolutional weights to reduce resource consumption. However, removing channels is non-trivial for multi-branch segments of a model, which can introduce extra memory copies at inference time. These copies incur increase latency — so much…
PDP: Parameter-free Differentiable Pruning is All You Need
July 24, 2023research area Methods and Algorithms, research area Tools, Platforms, Frameworksconference ICML, conference NeurIPS
DNN pruning is a popular way to reduce the size of a model, improve the inference latency, and minimize the power consumption on DNN accelerators. However, existing approaches might be too complex, expensive or ineffective to apply to a variety of vision/language tasks, DNN architectures and to honor structured pruning constraints. In this paper, we propose an efficient yet effective train-time pruning scheme, Parameter-free Differentiable…

Our research in machine learning breaks new ground every day.