content type paperpublished July 2025
Overcoming Vocabulary Constraints with Pixel-level Fallback
AuthorsJonas F. Lotz†**, Hendra Setiawan, Stephan Peitz, Yova Kementchedjhieva‡
Overcoming Vocabulary Constraints with Pixel-level Fallback
AuthorsJonas F. Lotz†**, Hendra Setiawan, Stephan Peitz, Yova Kementchedjhieva‡
Subword tokenization requires balancing computational efficiency and vocabulary coverage, which often leads to suboptimal performance on languages and scripts not prioritized during training. We propose to augment pretrained language models with a vocabulary-free encoder that generates input embeddings from text rendered as pixels. Through experiments on English-centric language models, we demonstrate that our approach substantially improves machine translation performance and facilitates effective cross-lingual transfer, outperforming tokenizer-based methods. Furthermore, we find that pixel-based representations outperform byte-level approaches and standard vocabulary expansion. Our approach enhances the multilingual capabilities of monolingual language models without extensive retraining and reduces decoding latency via input compression.
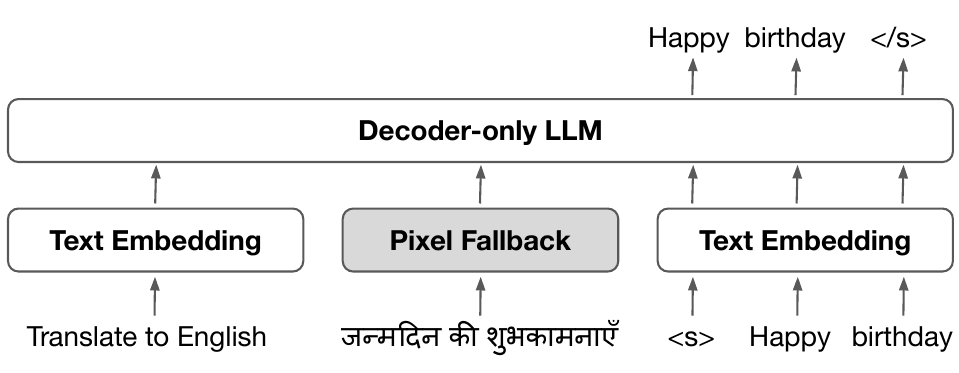
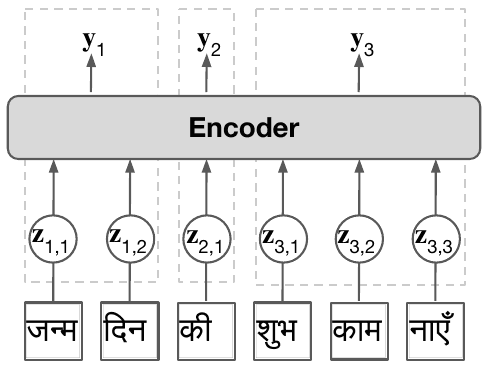
Cut Your Losses in Large-Vocabulary Language Models
February 7, 2025research area Methods and Algorithmsconference ICLR
As language models grow ever larger, so do their vocabularies. This has shifted the memory footprint of LLMs during training disproportionately to one single layer: the cross-entropy in the loss computation. Cross-entropy builds up a logit matrix with entries for each pair of input tokens and vocabulary items and, for small models, consumes an order of magnitude more memory than the rest of the LLM combined. We propose Cut Cross-Entropy (CCE), a…
Training Large-Vocabulary Neural Language Model by Private Federated Learning for Resource-Constrained Devices
December 18, 2023research area Privacy, research area Speech and Natural Language Processingconference ICASSP
*Equal Contributors
Federated Learning (FL) is a technique to train models using data distributed across devices. Differential Privacy (DP) provides a formal privacy guarantee for sensitive data. Our goal is to train a large neural network language model (NNLM) on compute-constrained devices while preserving privacy using FL and DP. However, the DP-noise introduced to the model increases as the model size grows, which often prevents…

Our research in machine learning breaks new ground every day.