content type highlightpublished December 3, 2018
Optimizing Siri on HomePod in Far‑Field Settings
AuthorsAudio Software Engineering and Siri Speech Team
Optimizing Siri on HomePod in Far‑Field Settings
AuthorsAudio Software Engineering and Siri Speech Team
The typical audio environment for HomePod has many challenges — echo, reverberation, and noise. Unlike Siri on iPhone, which operates close to the user’s mouth, Siri on HomePod must work well in a far-field setting. Users want to invoke Siri from many locations, like the couch or the kitchen, without regard to where HomePod sits. A complete online system, which addresses all of the environmental issues that HomePod can experience, requires a tight integration of various multichannel signal processing technologies. Accordingly, the Audio Software Engineering and Siri Speech teams built a system that integrates both supervised deep learning models and unsupervised online learning algorithms and that leverages multiple microphone signals. The system selects the optimal audio stream for the speech recognizer by using top-down knowledge from the “Hey Siri” trigger phrase detectors. In this article, we discuss the machine learning techniques we use for online signal processing, as well as the challenges we faced and our solutions for achieving environmental and algorithmic robustness while ensuring energy efficiency.
HomePod is a home speaker with smart home capabilities including far-field Siri, which the user can control through speech even while music is playing. Siri on HomePod is designed to work in challenging usage scenarios such as:
Under all these conditions, Siri on HomePod should respond and correctly recognize commands.
This article describes HomePod’s multichannel signal processing system with emphasis on these approaches:
The system uses six microphones and runs the multichannel signal processing continuously on an Apple A8 chip, including when the Homepod is run in its lowest power state to save energy. The multichannel filtering constantly adapts to changing noise conditions and moving talkers.
Other state-of-the-art systems use multi-microphone processing to enhance speech, but typically focus only on a subset of problems such as dereverberation [1] and noise suppression [2]. To suppress the undesired signal components, a speech enhancement system must learn the desired and undesired signal characteristics using supervised or unsupervised learning methods. Recently, speech enhancement performance has improved substantially due to deep learning. In [2], for example, the top performing techniques learn the speech presence probability using a deep neural network (DNN), which drives multichannel noise suppression filters. However, these systems are commonly built assuming that the full speech utterance is available during runtime and that the system performs batch processing to take advantage of all speech samples during the voice command [3]. This setup increases latency and precludes speech enhancement for always-listening modes on home assistant devices, including trigger phrase detection and endpointing functionalities. The assumptions behind batch speech enhancement systems are unrealistic for HomePod because the acoustic conditions are unpredictable, and the start and end points of the voice commands aren’t available beforehand.
Far-field speech recognition becomes more challenging when another active talker, like a person or a TV, is present in the same room with the target talker. In this scenario, voice trigger detection, speech decoding, and endpointing can be substantially degraded if the voice command isn’t separated from the interfering speech components. Traditionally, researchers tackle speech source separation using either unsupervised methods, like independent component analysis and clustering [4], or deep learning [5, 6]. These techniques can improve automatic speech recognition in conferencing applications or on batches of synthetic speech mixtures where each speech signal is extracted and transcribed [6, 7]. Unfortunately, the usability of these batch techniques in far-field voice command-driven interfaces is very limited. Furthermore, the effect of source separation on voice trigger detection, such as that used with “Hey Siri”, has never been investigated previously. Finally, it’s crucial to separate far-field mixtures of competing signals online to avoid latencies and to select and decode only the target stream containing the voice command.
The multichannel far-field signal model can be written in the frequency domain as:
where:
The aim of the multichannel signal processing system is to extract one of the speech sources in s by removing echo, reverberation, noise, and competing talkers to improve intelligibility. Figure 1 shows an overview of our system.
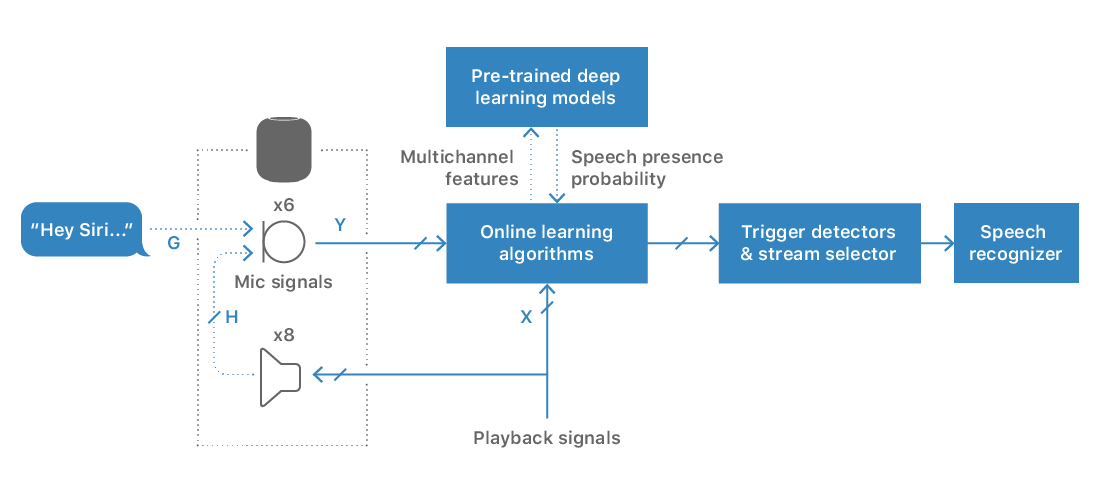
Due to the close proximity of the loudspeakers to the microphones on HomePod, the playback signal can be significantly louder than a user’s voice command at the microphone positions, especially when the user moves away from the device. In fact, the echo signals may be 30-40 dB louder than the far-field speech signals, resulting in the trigger phrase being undetectable on the microphones during loud music playback. Siri on HomePod implements the Multichannel Echo Cancellation (MCEC) algorithm, which uses a set of linear adaptive filters to model the multiple acoustic paths between the loudspeakers and the microphones to cancel the acoustic coupling. Two problems limit the MCEC from completely removing the device’s own playback signal from the microphones in practice:
Therefore, a residual echo suppressor (RES) is required to remove remaining playback content after the MCEC. We discuss our deep learning approach to residual echo suppression in the next section.
At loud playback volumes, the MCEC usually provides insufficient echo cancellation for successful trigger phrase detection, resulting in residual echo levels which are 10 to 20 dB above the far-field speech. The RES is designed to suppress nonlinear components of the echo signal that aren’t being modeled by the linear MCEC. The RES also mitigates residual linear echo, especially in the presence of double-talk and echo path changes.
Typical data-driven residual echo suppression approaches [10, 11] extract input features from reference and echo-canceled signals, and use the network to apply suppression gains directly to the echo-canceled signal. In our approach to RES, a DNN takes in multiple input features and outputs an estimate of a speech activity mask that is used as an input Speech Presence Probability (SPP) for a Multichannel Wiener Filter (MCWF). The input features are extracted from the echo-canceled signals along with the linear echo estimate provided by the MCEC.
The mask-based echo suppression approach has several benefits:
As a speech source moves further away from the microphones, multiple reflections from the room create reverberation tails that decrease the quality and intelligibility of the target speech. The signal captured by a microphone can be characterized by the direct sound (speech without any reflection), the early reflections, and the late reverberation. The late reverberation can severely degrade speech recognizer performance [12, 13]. Siri on HomePod continuously monitors the room characteristics and removes the late reverberation while preserving the direct and early reflection components in the microphone signals.
In addition to reverberation, far-field speech is typically contaminated by noise from home appliances, HVAC, outdoor sounds entering through windows, and various other noise sources. Mask-based MCWF is a powerful tool for noise-robust far-field speech recognition in batch conditions [3,14]. Unlike traditional single-channel approaches, the MCWF is a signal-dependent beamformer that can steer nulls toward spatially localized noise sources without distorting the target speech. This capability is possible when the SPP is estimated correctly, using either statistical models [14,15] or learned by DNNs [3]. When processed in batch, this approach assumes that noise and speech sources aren’t moving during the active speech segments.
These state-of-the-art speech enhancement methods create a fixed filter for each utterance using all of the aggregate estimations of speech and noise to enhance the speech before feeding it to the recognizer. A DNN trained to recognize the spectral characteristics of speech and noise can reduce noise even more for this problem of mask estimation. However, to deal with the constantly changing acoustic environment, we require an online noise reduction system that can track environmental noise with low latency. We built an online MCWF that estimates speech and noise statistics using only the current and past microphone signals. In addition, we deployed a DNN that predicts the SPP and drives the MCWF to steer directional nulls toward interfering noise sources.
We trained the DNN on internally collected data using both diffuse and directional noises, as well as continuous and discrete noises that are difficult to model statistically. We synthetically mixed near-end speech-only recordings and noise-only recordings to produce speech-plus-noise recordings. This mix allows us to generate ground truth (oracle) targets for the SPP. We calculated the input features to the DNN from the dereverberated signal and the reverberation estimate. The output features are the speech activity mask calculated from the near-end speech and the speech-plus-noise mixture.
The corruption of target speech by other interfering talkers is challenging for both speech enhancement and recognition. Blind source separation (BSS) is a technique that can simultaneously separate multiple audio sources into individual audio streams in an unsupervised fashion [4]. However, selecting the correct audio stream from the multiple output streams remains a challenge and requires top-down knowledge of a user’s voice command. In addition to using the trigger phrase “Hey Siri” as a strong acoustic cue to identify the target stream, we developed a competing talker separation approach and a deep learning stream selection system.
We deployed a computationally lightweight unsupervised learning method for blind source separation to decompose the microphone array signals into independent audio streams. The method used leverages the statistical property of independence between the competing sources and the correlation of the spectral components of each source and is numerically stable and fast‐converging. Our BSS algorithm learns the acoustic channel at every new input audio frame directly from the microphone signals, and separates the competing sources with a computational complexity of per source at a given sub-band. It outputs streams given input channels. Although the algorithm doesn’t suffer from the frequency permutation ambiguity known in other traditional approaches such as independent component analysis, the arrangement of the output sources can’t be known ahead of time. Additional prior knowledge is then needed to identify the target stream.
The noise-plus-residual-echo suppression and source separation algorithms play complementary roles in the proposed system. They jointly learn the acoustic environment and address the diverse conditions in which HomePod can be used, for example, quiet environment, noisy background, loud playback, and competing talker. Because prior information on the acoustic scene of interest is difficult to obtain during runtime, and because the arrangement of the output streams of BSS is arbitrary, we developed a deep learning–based stream selection system to determine the best audio stream using the voice trigger. Our system essentially leverages the on-device DNN-powered “Hey Siri” detector described in [16], and continuously monitors the audio streams. When “Hey Siri” is detected, each stream is assigned a goodness score. The stream with the highest score is selected and sent to Siri for speech recognition and task completion.
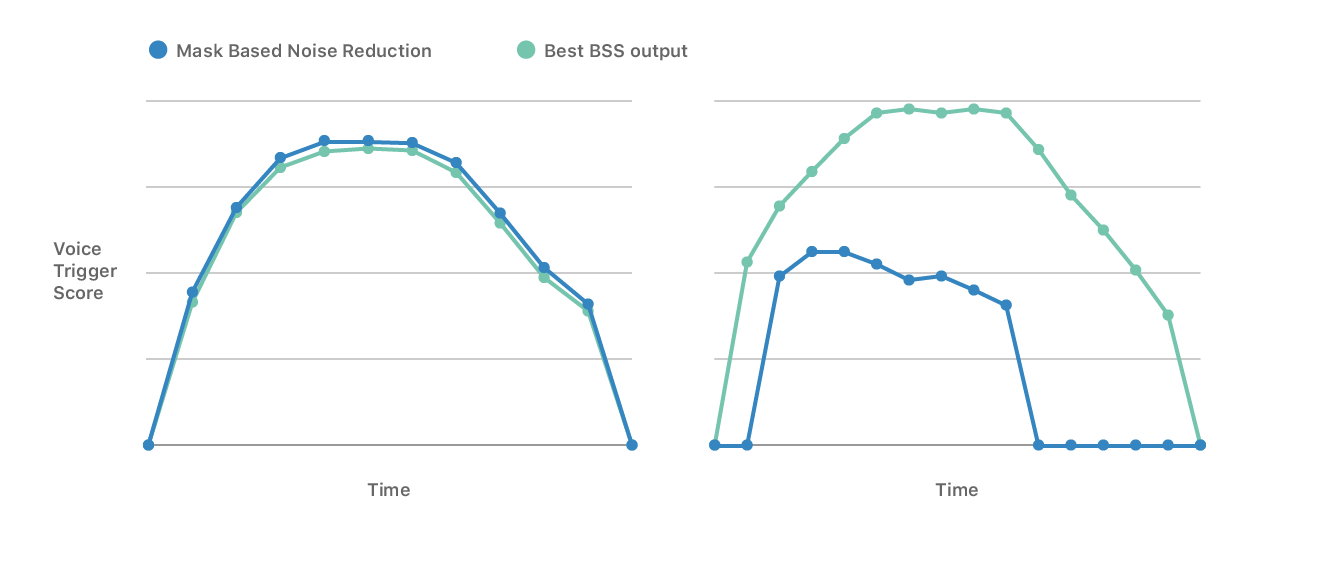
Figure 2 depicts examples of trigger scores computed during “Hey Siri” for mask-based noise reduction in blue and the best BSS stream in green. The left plot shows data obtained in a relatively quiet acoustic condition. You can see that mask-based noise reduction is optimal. The data shown in the right plot is from a more challenging acoustic condition — a speech signal corrupted by a loud television playing nearby. The BSS stream has a large score and should be selected over mask-based noise reduction.
We evaluated the performance of the proposed speech processing system on a large speech test set recorded on HomePod in several acoustic conditions:
In these recordings, we varied the locations of HomePod and the test subjects to cover different use cases, for example, in living room or kitchen environments where HomePod was placed against the wall or in the middle of the room.
We investigated the performance of our system in a real setup, where the trigger detection and subsequent voice command recognition jointly affect the user experience. Therefore, we report the objective Siri performance metrics, namely the false reject (FR) and the word error rates (WERs). We chose the tradeoff between false alarm (FA) rates and FRs experimentally to guarantee the best user experience. Because triggered utterances can be different using one processing algorithm or another in different acoustic conditions, the WER numbers are directly influenced by the trigger performance. We discuss this issue below. In Audio Examples, we give some audio examples to demonstrate the subjective quality of the signals enhanced by our algorithms.
Figure 3 shows the FRs of our proposed speech enhancement system based on deep learning. The triggering threshold is the same in all conditions. Mask-based noise reduction is suitable for most acoustic conditions except for the multi-talker and directional noise conditions, which are well handled by our stream selection system. For example in the competing talker case, the absolute FR improvement of the multistream system is 29.0% when compared to mask-based noise reduction, which has no source separation capability, and 30.3% when compared to the output of the baseline DSP system (that includes echo cancellation and dereveberation).
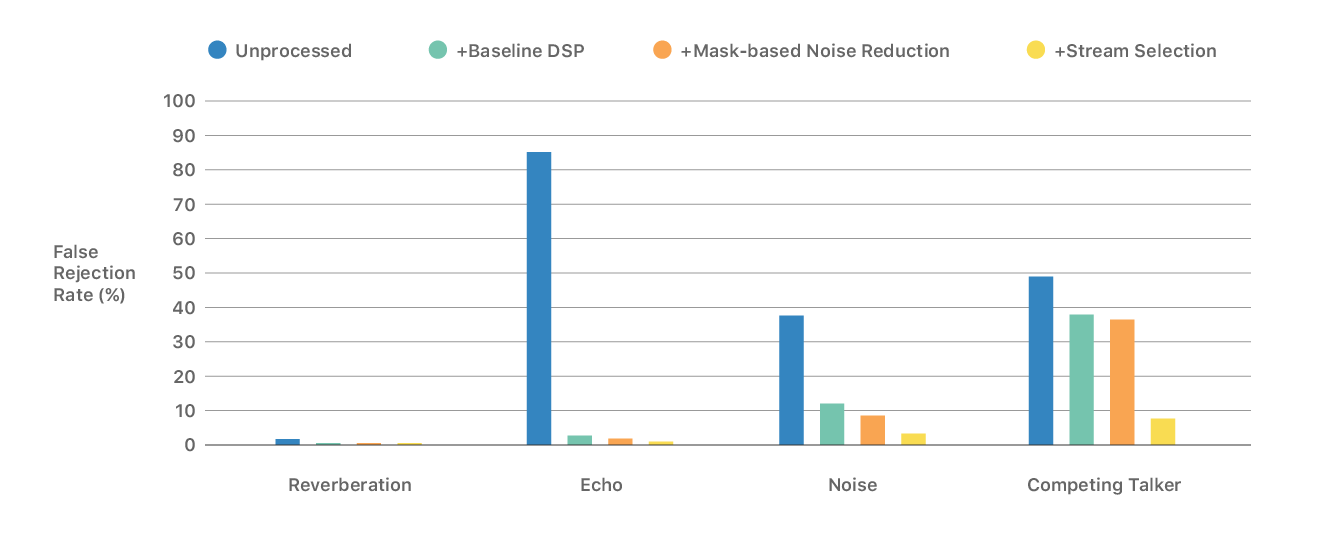
The gap between mask-based noise reduction and the multistream system becomes smaller in other acoustic conditions. Overall, there is a clear trend of healthy FR improvement when our mask-based noise reduction and source separation techniques (stream selection) are used.
Figure 4 shows the WERs achieved by combining the multichannel signal processing based on deep learning with the speech recognizer that we adapted on different live data (some of it processed with our online multichannel signal processing). The blue portion of the bar represents the error rate of the triggered utterances, and the green portion represents the error rate due to falsely rejected utterances (missed utterances). Note that different numbers of words are used for evaluation in the blue portion of the bars since the corresponding number of false rejections are significantly different for each case.
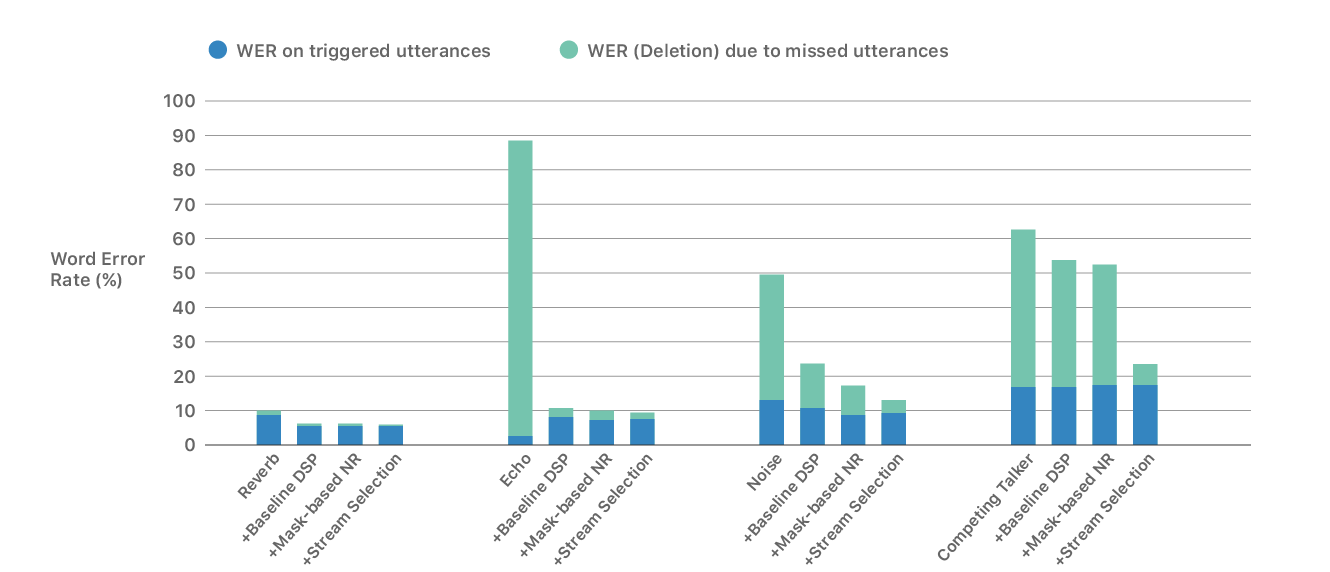
It is obvious that the optimal integration of our speech processing technologies substantially improves the overall WERs across conditions. More specifically, the WER relative improvements are about 40%, 90%, 74%, and 61% in the four investigated acoustic conditions of reverberant speech only, playback, loud background noise, and competing talker, respectively.
These results also indicate that across most conditions, the WERs on the triggered utterances (blue bar) achieved by mask-based noise reduction and the multistream system are very similar, except for the competing talker and noise cases. As illustrated by the FR rates in Figure 3, our signal processing algorithms can have significantly different impacts on the voice trigger detection and stream selection. Different utterances can be triggered using one algorithm or another, and these utterances have different numbers of words. This clearly impacts the final WERs, and direct head-to-head comparisons of the different methods might not be straightforward.
The main conclusion that we can draw from Figure 4 is that in addition to the great improvement in FRs using the multistream system demonstrated in Figure 3, our deep learning–based signal processing significantly reduces the word error rates. This improvement allows the user to interact easily with HomePod even in the presence of loud playback and external acoustic distortions like reverberation, noise, and competing talker.
We implemented our online multichannel signal processing system using Apple’s Accelerate Framework for vector and matrix math and neural network inference, and we profiled the system on a single core of an Apple A8 chip. Our proposed speech enhancement system consumes less than 15% of a single core of an A8 chip running at 1.4 GHz.
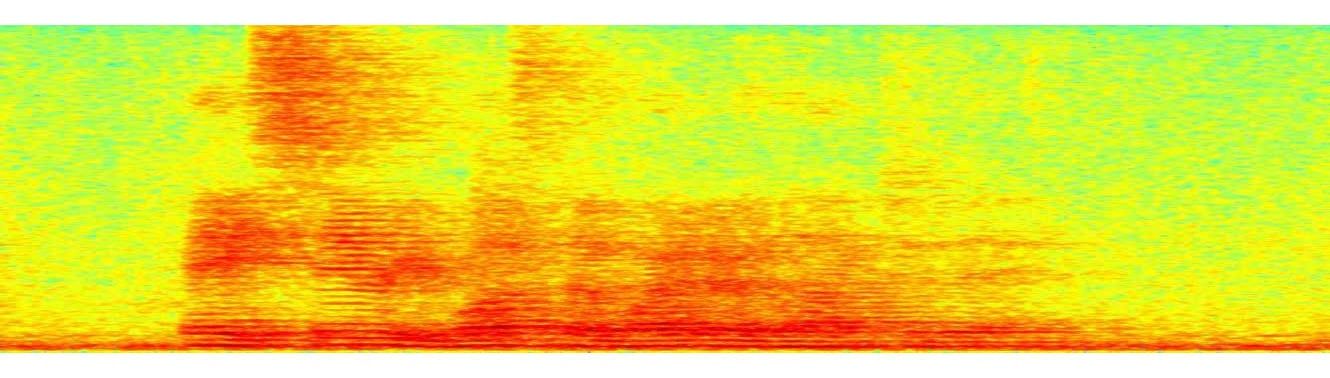
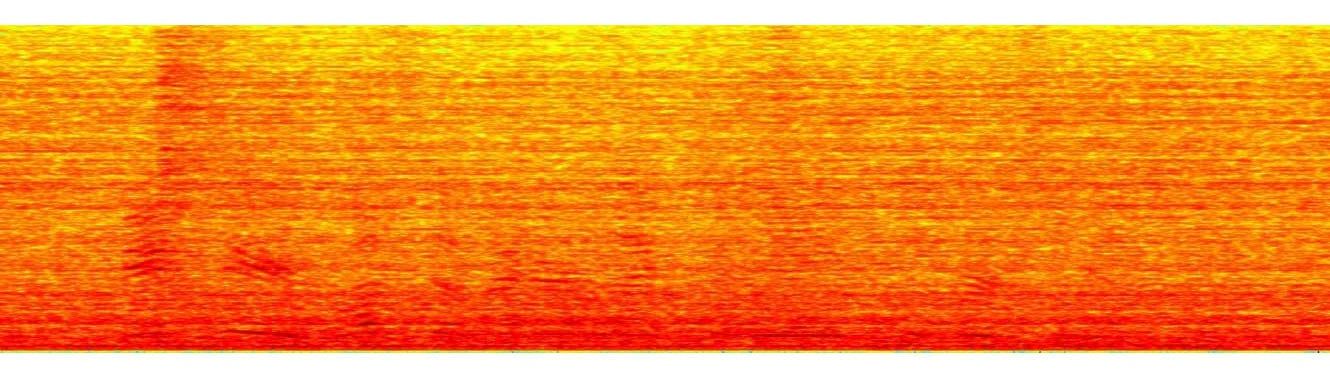
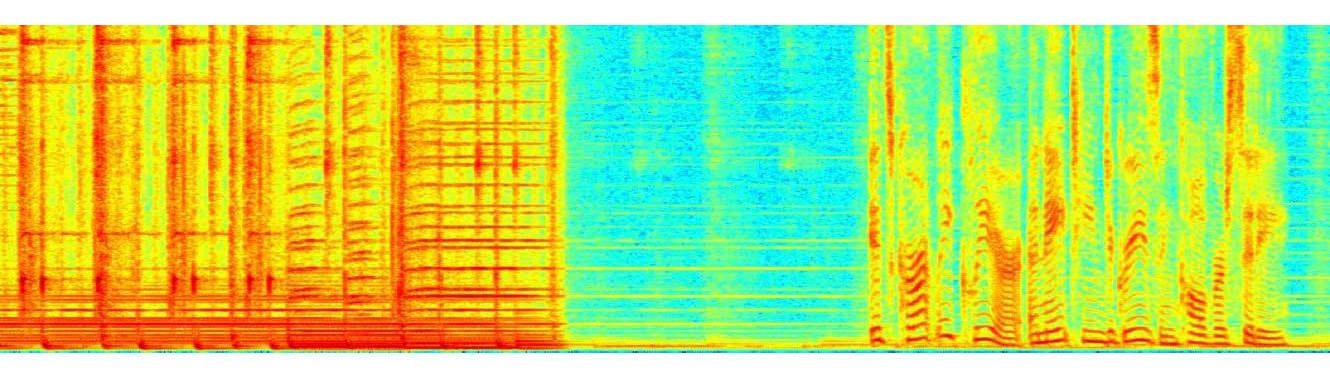
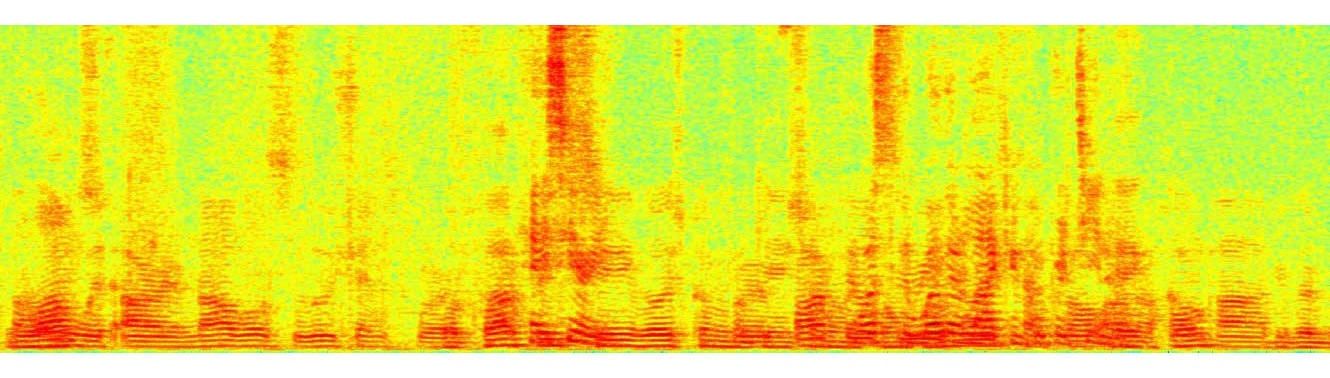
You can listen to the following audio examples that showcase the enhancement effects of our processing in presence of reverberation with quiet background, additive noise generated by a dishwasher, playback music, and interfering talkers. The respective spectrograms are shown in Figures 5, 6, 7, and 8. From the subjective listening and visual inspection of each of these examples, you should be able to hear that the acoustic distortions are significantly reduced, which greatly facilitates the speech recognition task across conditions.





[1] K. Kinoshita, M. Delcroix, T. Yoshioka, T. Nakatani, A. Sehr, W. Kellermann, and R. Maas. The REVERB challenge: A common evaluation framework for dereverberation and recognition of reverberant speech, in Proc. IEEE WASPAA, 2013.
[2] The 4th CHiME Speech Separation and Recognition Challenge, 2016.
[3] H. Erdogan, J.R. Hershey, S. Watanabe, M. Mandel, and J. Le Roux. Improved MVDR beamforming using single-channel mask prediction networks, in Proc. ISCA Interspeech, 2016.
[4] M.S. Pedersen, J. Larsen, U. Kjems, and L.C. Parra. A survey of convolutive blind source separation methods, Multichannel Speech Processing Handbook, 2007.
[5] J.R. Hershey, Z. Chen, J. Le Roux, and S. Watanabe. Deep clustering: discriminative embeddings for segmentation and separation, in Proc. IEEE ICASSP, 2016.
[6] D. Yu, M. Kolbæk, Z.-H. Tan, and J. Jensen. Permutation invariant training of deep models for speaker-independent multi-talker speech separation, in Proc. IEEE ICASSP, 2017.
[7] T. Hori, S. Araki, T. Yoshioka, M. Fujimoto, S. Watanabe, T. Oba, A. Ogawa, K. Otsuka, D. Mikami, K. Kinoshita, T. Nakatani, A. Nakamura, and J. Yamato. Low-latency real-time meeting recognition and understanding using distant microphones and omni-directional camera, IEEE Transactions on Audio, Speech and Language Processing, vol. 20, no. 2, pp. 499–513, 2012.
[8] D.A. Bendersky, J.W. Stokes, and H.S. Malvar. Nonlinear residual acoustic echo suppression for high levels of harmonic distortion, In Proc. IEEE ICASSP, 2008.
[9] M.M. Sondhi, D.R. Morgan, and J.L. Hall. Stereophonic acoustic echo cancellation-an overview of the fundamental problem, IEEE Signal Processing Letters, vol. 2, no. 8, pp. 148–151, 1995.
[10] A. Schwartz, C. Hofmann, and W. Kellermann. Spectral feature-based nonlinear residual echo suppression, in Proc. IEEE WASPAA, 2013.
[11] C. M. Lee, J. W. Shin, and N. S. Kim. DNN-based residual echo suppressor, in Proc. ISCA Interspeech, 2015.
[12] T. Yoshioka, A. Sehr, M. Delcroix, K. Kinoshita, R. Maas, T. Nakatani, and W. Kellermann. Making machines understand us in reverberant rooms: robustness against reverberation for automatic speech recognition, IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 114–126, 2012.
[13] A. Jukić, T. van Waterschoot, T. Gerkmann, and S. Doclo. Group sparsity for MIMO speech dereverberation, in Proc. IEEE WASPAA, 2015.
[14] M. Souden, S. Araki, K. Kinoshita, T. Nakatani, and H. Sawada. A multichannel MMSE-based framework for speech source separation and noise reduction, IEEE Transactions on Audio, Speech, and Language Processing, vol. 21, no. 9, pp. 1913–1928, 2013.
[15] M. Souden, J. Chen, J. Benesty, and S. Affes. An integrated solution for online multichannel noise tracking and reduction, IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2159–2169, 2011.
[16] Siri Team. Hey Siri: An On-device DNN-powered Voice Trigger for Apple’s Personal Assistant, Apple Machine Learning Research
A growing number of consumer devices, including smart speakers, headphones, and watches, use speech as the primary means of user input. As a result, voice trigger detection systems—a mechanism that uses voice recognition technology to control access to a particular device or feature—have become an important component of the user interaction pipeline as they signal the start of an interaction between the user and a device. Since these systems are deployed entirely on-device, several considerations inform their design, like privacy, latency, accuracy, and power consumption.
Hey Siri: An On-device DNN-powered Voice Trigger for Apple’s Personal Assistant
October 1, 2017research area Speech and Natural Language Processing
The “Hey Siri” feature allows users to invoke Siri hands-free. A very small speech recognizer runs all the time and listens for just those two words. When it detects “Hey Siri”, the rest of Siri parses the following speech as a command or query. The “Hey Siri” detector uses a Deep Neural Network (DNN) to convert the acoustic pattern of your voice at each instant into a probability distribution over speech sounds. It then uses a temporal integration process to compute a confidence score that the phrase you uttered was “Hey Siri”. If the score is high enough, Siri wakes up. This article takes a look at the underlying technology. It is aimed primarily at readers who know something of machine learning but less about speech recognition.

Our research in machine learning breaks new ground every day.