content type paperpublished July 2025
Visatronic: A Multimodal Decoder-Only Model for Speech Synthesis
AuthorsAkshita Gupta†, Tatiana Likhomanenko, Karren Yang, Richard He Bai, Zakaria Aldeneh, Navdeep Jaitly
Visatronic: A Multimodal Decoder-Only Model for Speech Synthesis
AuthorsAkshita Gupta†, Tatiana Likhomanenko, Karren Yang, Richard He Bai, Zakaria Aldeneh, Navdeep Jaitly
The rapid progress of foundation models and large language models (LLMs) has fueled significantly improvement in the capabilities of machine learning systems that benefit from mutlimodal input data. However, existing multimodal models are predominantly built on top of pre-trained LLMs, which can limit accurate modeling of temporal dependencies across other modalities and thus limit the model’s ability to jointly process and leverage multimodal inputs. To specifically investigate the alignment of text, video, and speech modalities in LLM-style (decoder-only) models, we consider a simplified multimodal generation task, Video-Text to Speech (VTTS): speech generation conditioned on both its corresponding text and video of talking people. The ultimate goal is to generate speech that not only follows the text but also aligns temporally with the video and is consistent with the facial expressions. In this paper, we first introduce Visatronic, a unified multimodal decoder-only transformer model that adopts an LLM-style architecture to embed visual, textual, and speech inputs into a shared subspace, treating all modalities as temporally aligned token streams. Next, we carefully explore different token mixing strategies to understand the best way to propagate information from the steps where video and text conditioning is input to the steps where the audio is generated. We extensively evaluate Visatronic on the challenging VoxCeleb2 dataset and demonstrate zero-shot generalization to LRS3, where Visatronic, trained on VoxCeleb2, achieves a 4.5% WER, outperforming prior SOTA methods trained only on LRS3, which report a 21.4% WER. This highlights significant gains across objective metrics, such as word error rate and phoneme-level synchronization, and subjective assessments of naturalness and expressiveness. Additionally, we propose a new objective metric, TimeSync, specifically designed to measure phoneme-level temporal alignment between generated and reference speech, further ensuring synchronization quality.
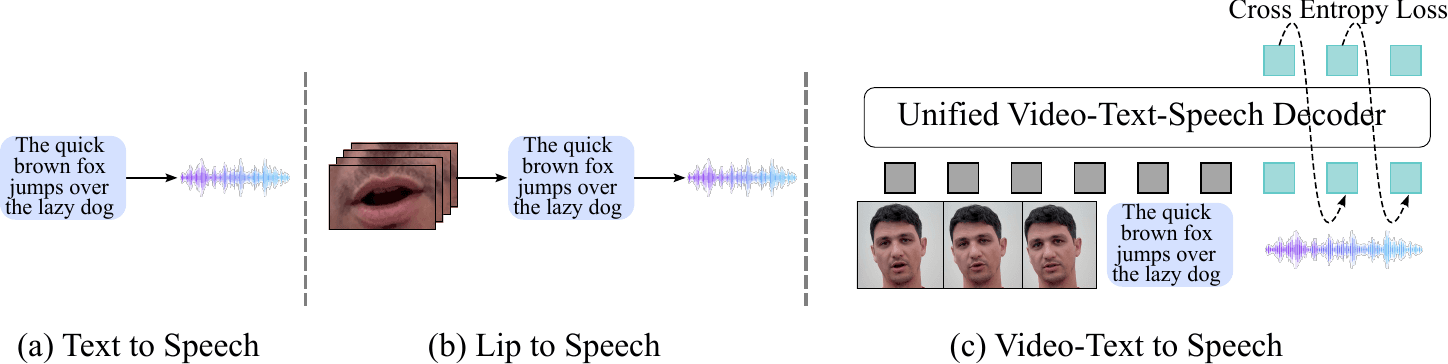
Figure 1: Visatronic overview. In addition to existing text to speech (left) and lips to speech tasks (middle), we address multimodal generative task (right), video-text to speech (VTTS), where the model is conditioned on the video of talking people and corresponding text transcriptions in order to generate speech.
Breaking Down Video LLM Benchmarks: Knowledge, Spatial Perception, or True Temporal Understanding?
October 27, 2025research area Computer Vision, research area Methods and AlgorithmsWorkshop at NeurIPS
This paper was accepted at the Evaluating the Evolving LLM Lifecycle Workshop at NeurIPS 2025.
Existing video understanding benchmarks often conflate knowledge-based and purely image-based questions, rather than clearly isolating a model’s temporal reasoning ability, which is the key aspect that distinguishes video understanding from other modalities. We identify two major limitations that obscure whether higher scores truly indicate stronger…
ETVA: Evaluation of Text-to-Video Alignment via Fine-grained Question Generation and Answering
June 30, 2025research area Computer Vision, research area Methods and Algorithmsconference ICCV
Precisely evaluating semantic alignment between text prompts and generated videos remains a challenge in Text-to-Video (T2V) Generation. Existing text-to-video alignment metrics like CLIPScore only generate coarse-grained scores without fine-grained alignment details, failing to align with human preference. To address this limitation, we propose ETVA, a novel Evaluation method of Text-to-Video Alignment via fine-grained question generation and…

Our research in machine learning breaks new ground every day.