Multimodal large language models (MLLMs) excel at 2D visual understanding but remain limited in their ability to reason about 3D space. In this work, we leverage large-scale high-quality 3D scene data with open-set annotations to introduce 1) a novel supervised fine-tuning dataset and 2) a new evaluation benchmark, focused on indoor scenes. Our Cubify Anything VQA (CA-VQA) data covers diverse spatial tasks including spatial relationship prediction, metric size and distance estimation, and 3D grounding. We show that CA-VQA enables us to train MM-Spatial, a strong generalist MLLM that also achieves state-of-the-art performance on 3D spatial understanding benchmarks, including our own. We show how incorporating metric depth and multi-view inputs (provided in CA-VQA) can further improve 3D understanding, and demonstrate that data alone allows our model to achieve depth perception capabilities comparable to dedicated monocular depth estimation models.
* Equal Contributors
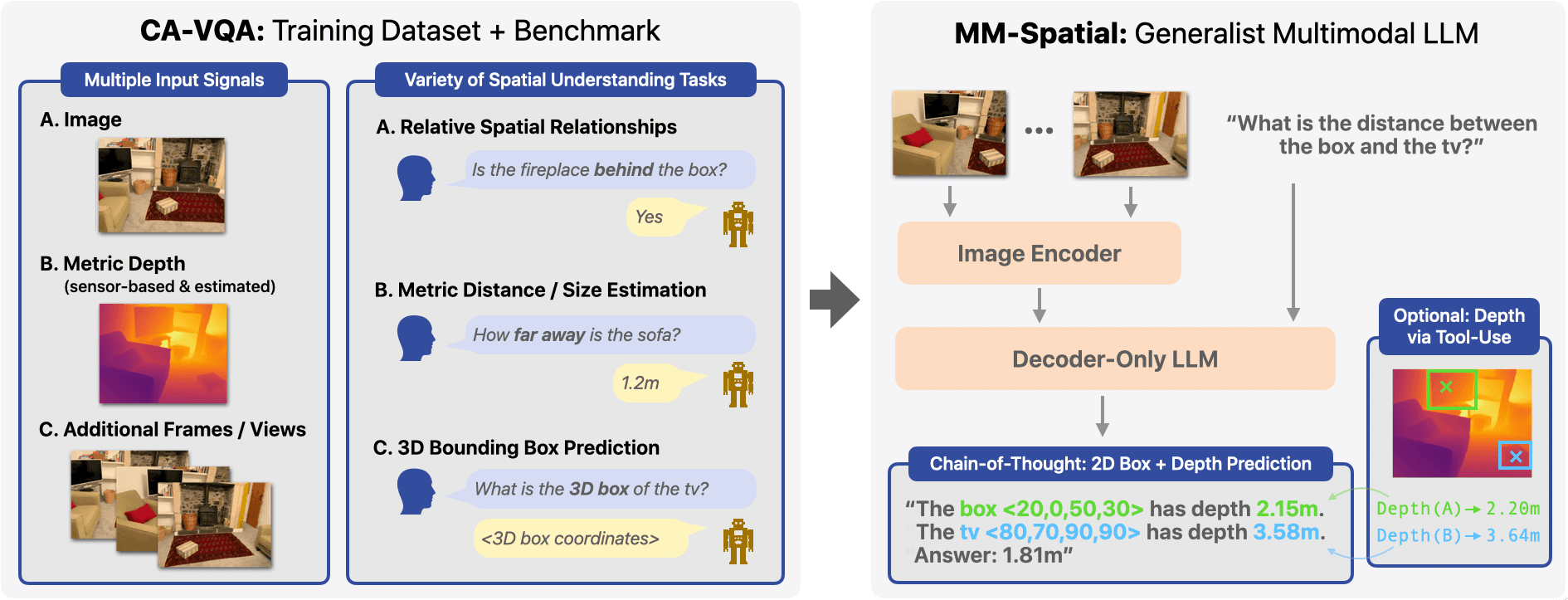
Figure 1: (Left) We generate the Cubify Anything VQA (CA-VQA) dataset and benchmark, covering various 1) input signals: single image, metric depth (sensor-based and estimated), multi-frame/-view, and 2) spatial understanding tasks: e.g., relationship prediction, metric estimation, 3D grounding. (Right) We train MM-Spatial, a generalist multimodal LLM that excels at 3D spatial understanding. It supports Chain-of-Thought spatial reasoning involving 2D grounding and depth estimation, and can also leverage depth input via tool-use.
We introduce ImmerseDiffusion, an end-to-end generative audio model that produces 3D immersive soundscapes conditioned on the spatial, temporal, and environmental conditions of sound objects.
ImmerseDiffusion is trained to generate first-order ambisonics (FOA) audio, which is a conventional spatial audio format comprising four channels that can be rendered to multichannel spatial output.
The proposed generative system is composed of a spatial…
High-quality 3D ground-truth shapes are critical for 3D object reconstruction evaluation.
However, it is difficult to create a replica of an object in reality, and even 3D reconstructions generated by 3D scanners have artefacts that cause biases in evaluation. To address this issue, we introduce a novel multi-view RGBD dataset captured using a mobile device, which includes highly precise 3D ground-truth annotations for 153 object models…