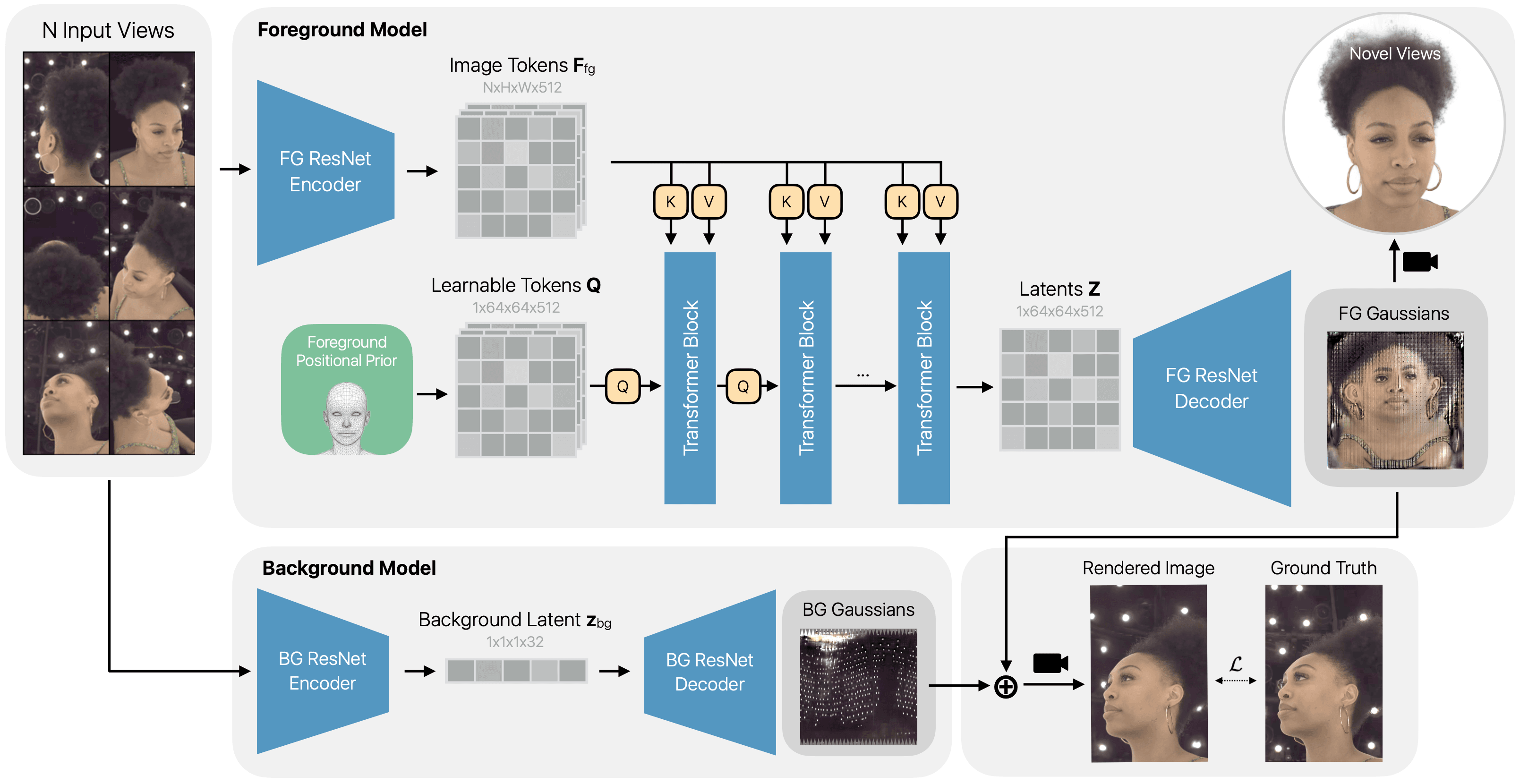
We propose HeadsUp, a scalable feed-forward method for reconstructing high-quality 3D Gaussian heads from large-scale multi-camera setups. Our method employs an efficient encoder-decoder architecture that compresses input views into a compact latent representation. This latent representation is then decoded into a set of UV-parameterized 3D Gaussians anchored to a neutral head template. This UV representation decouples the number of 3D Gaussians from the number and resolution of input images, enabling training with many high-resolution input views. We train and evaluate our model on an internal dataset with more than 10,000 subjects, which is an order of magnitude larger than existing multi-view human head datasets. HeadsUp achieves state-of-the-art reconstruction quality and generalizes to novel identities without test-time optimization. We extensively analyze the scaling behavior of our model across identities, views, and model capacity, revealing practical insights for quality-compute trade-offs. Finally, we highlight the strength of our latent space by showcasing two downstream applications: generating novel 3D identities and animating the 3D heads with expression blendshapes.
- † ETH Zurich
- ** Work done while at Apple
Figure 1: Overview of HeadsUp. Our method reconstructs high-fidelity 3D Gaussian heads from multi-view images. Given a set of input views, our model utilizes a transformer-based encoder and a 3D Gaussian decoder to predict UV-parameterized 3D Gaussians for both the foreground and background. The model is trained end-to-end using a combination of photometric and perceptual supervision.