We introduce exclusive self attention (XSA), a simple modification of self attention (SA) that improves Transformer’s sequence modeling performance. The key idea is to constrain attention to capture only information orthogonal to the token’s own value vector (thus excluding information of self position), encouraging better context modeling. Evaluated on the standard language modeling task, XSA consistently outperforms SA across model sizes up to 2.7B parameters and shows increasingly larger gains as sequence length grows.
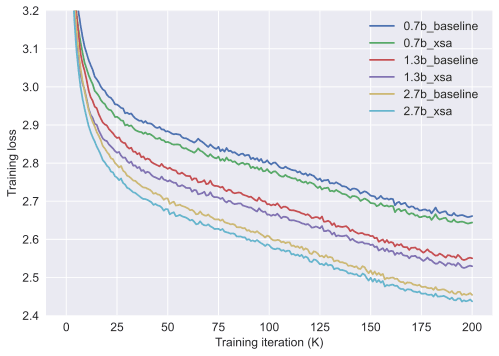
Figure 1: Training loss curves of XSA vs baseline Transformers on the FineWeb100B dataset.
Related readings and updates.
Self-attention and masked self-attention are at the heart of Transformers’ outstanding success. Still, our mathematical understanding of attention, in particular of its Lipschitz properties — which are key when it comes to analyzing robustness and expressive power — is incomplete. We provide a detailed study of the Lipschitz constant of self-attention in several practical scenarios, discussing the impact of the sequence length and layer…
Hybrid Transformer and CTC Networks for Hardware Efficient Voice Triggering
October 6, 2020research area Speech and Natural Language Processingconference Interspeech
We consider the design of two-pass voice trigger detection systems. We focus on the networks in the second pass that are used to re-score candidate segments obtained from the first-pass. Our baseline is an acoustic model(AM), with BiLSTM layers, trained by minimizing the CTC loss. We replace the BiLSTM layers with self-attention layers. Results on internal evaluation sets show that self-attention networks yield better accuracy while requiring…

Discover opportunities in Machine Learning.
Our research in machine learning breaks new ground every day.