content type paperpublished June 2025
Disentangled Safety Adapters Enable Efficient Guardrails and Flexible Inference-Time Alignment
AuthorsKundan Krishna, Joseph Y Cheng, Charles Maalouf, Leon A Gatys
Disentangled Safety Adapters Enable Efficient Guardrails and Flexible Inference-Time Alignment
AuthorsKundan Krishna, Joseph Y Cheng, Charles Maalouf, Leon A Gatys
This paper was accepted at the Principled Design for Trustworthy AI, Interpretability, Robustness, and Safety across Modalities Workshop at ICLR 2026.
Existing paradigms for ensuring AI safety, such as guardrail models and alignment training, often compromise either inference efficiency or development flexibility. We introduce Disentangled Safety Adapters (DSA), a novel framework addressing these challenges by decoupling safety-specific computations from a task-optimized base model. DSA utilizes lightweight adapters that leverage the base model’s internal representations, enabling diverse and flexible safety functionalities with minimal impact on inference cost. Empirically, DSA-based safety guardrails substantially outperform comparably sized standalone models, notably improving hallucination detection (0.88 vs. 0.61 AUC on Summedits) and also excelling at classifying hate speech (0.98 vs. 0.92 on ToxiGen) and unsafe model inputs and responses (0.93 vs. 0.90 on AEGIS2.0 & BeaverTails). Furthermore, DSA-based safety alignment allows dynamic, inference-time adjustment of alignment strength and a fine-grained trade-off between instruction following performance and model safety. Importantly, combining the DSA safety guardrail with DSA safety alignment facilitates context-dependent alignment strength, boosting safety on StrongReject by 93% while maintaining 98% performance on MTBench — a total reduction in alignment tax of 8 percentage points compared to standard safety alignment fine-tuning. Overall, DSA presents a promising path towards more modular, efficient, and adaptable AI safety and alignment.
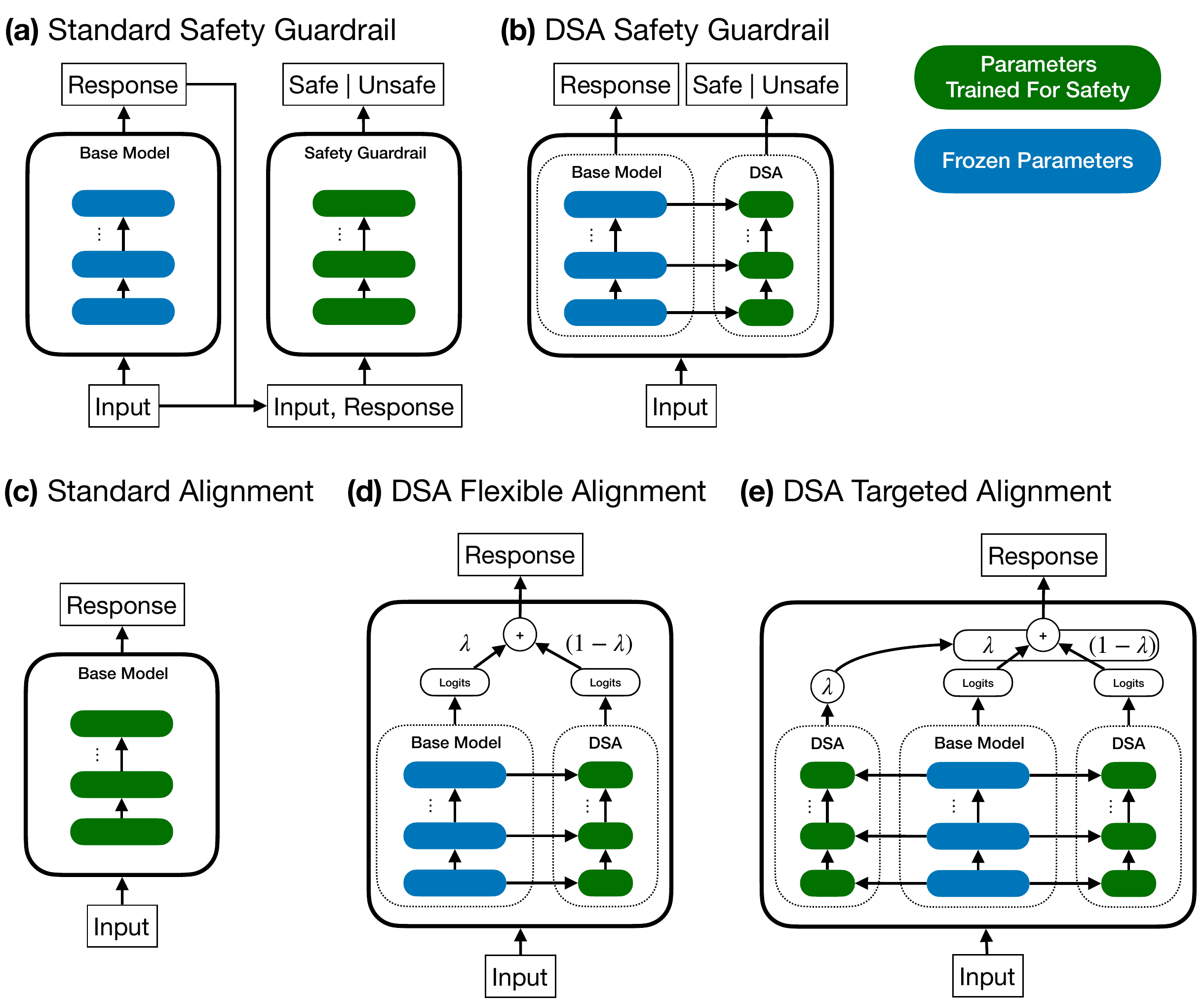
Figure 1: Overview of DSA architecture and how it compares to standard safety techniques.
SafetyPairs: Isolating Safety Critical Image Features with Counterfactual Image Generation
March 24, 2026research area Computer Vision, research area Speech and Natural Language ProcessingWorkshop at ICLR
This paper was accepted at the Principled Design for Trustworthy AI — Interpretability, Robustness, and Safety across Modalities Workshop at ICLR 2026.
What exactly makes a particular image unsafe? Systematically differentiating between benign and problematic images is a challenging problem, as subtle changes to an image, such as an insulting gesture or symbol, can drastically alter its safety implications. However, existing image safety…
VLSU: Mapping the Limits of Joint Multimodal Understanding for AI Safety
January 27, 2026research area Computer Vision, research area Speech and Natural Language Processingconference ICLR
Safety evaluation of multimodal foundation models often treats vision and language inputs separately, missing risks from joint interpretation where benign content becomes harmful in combination. Existing approaches also fail to distinguish clearly unsafe content from borderline cases, leading to problematic over-blocking or under-refusal of genuinely harmful content. We present Vision Language Safety Understanding (VLSU), a comprehensive…

Our research in machine learning breaks new ground every day.