content type paperpublished February 2026
Completed Hyperparameter Transfer across Modules, Width, Depth, Batch and Duration
AuthorsBruno Mlodozeniec†**, Pierre Ablin, Louis Béthune, Dan Busbridge, Michal Klein, Jason Ramapuram, Marco Cuturi
Completed Hyperparameter Transfer across Modules, Width, Depth, Batch and Duration
AuthorsBruno Mlodozeniec†**, Pierre Ablin, Louis Béthune, Dan Busbridge, Michal Klein, Jason Ramapuram, Marco Cuturi
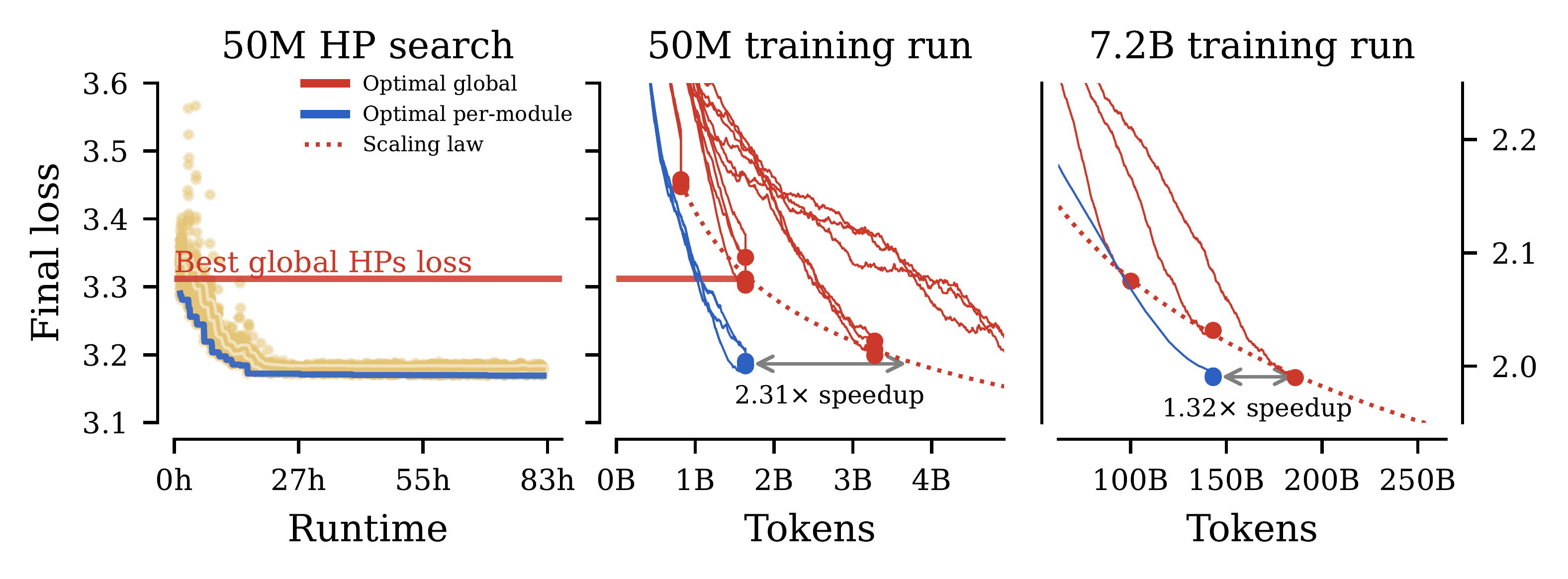
Hyperparameter tuning can dramatically impact training stability and final performance of large-scale models. Recent works on neural network parameterisations, such as μP, have enabled transfer of optimal global hyperparameters across model sizes. These works propose an empirical practice of search for optimal global base hyperparameters at a small model size, and transfer to a large size. We extend these works in two key ways. To handle scaling along most important scaling axes, we propose the Complete(d) Parameterisation that unifies scaling in width and depth — using an adaptation of CompleteP — as well as in batch-size and training duration. Secondly, with our parameterisation, we investigate per-module hyperparameter optimisation and transfer. We characterise the empirical challenges of navigating the high-dimensional hyperparameter landscape, and propose practical guidelines for tackling this optimisation problem. We demonstrate that, with the right parameterisation, hyperparameter transfer holds even in the per-module hyperparameter regime. Our study covers an extensive range of optimisation hyperparameters of modern models: learning rates, AdamW parameters, weight decay, initialisation scales, and residual block multipliers. Our experiments demonstrate significant training speed improvements in Large Language Models with the transferred per-module hyperparameters.
Privacy-Computation Trade-offs in Private Repetition and Metaselection
January 9, 2025research area Methods and Algorithms, research area Privacyconference FORC
A Private Repetition algorithm takes as input a differentially private algorithm with constant success probability and boosts it to one that succeeds with high probability. These algorithms are closely related to private metaselection algorithms that compete with the best of many private algorithms, and private hyperparameter tuning algorithms that compete with the best hyperparameter settings for a private learning algorithm. Existing algorithms…
Computational Bottlenecks of Training Small-Scale Large Language Models
October 29, 2024research area Methods and Algorithms, research area Speech and Natural Language ProcessingWorkshop at NeurIPS
This paper was accepted at the Efficient Natural Language and Speech Processing (ENLSP) Workshop at NeurIPS 2024.
While large language models (LLMs) dominate the AI landscape, Small-scale large Language Models (SLMs) are gaining attention due to cost and efficiency demands from consumers. However, there is limited research on the training behavior and computational requirements of SLMs. In this study, we explore the computational bottlenecks of…

Our research in machine learning breaks new ground every day.