content type paperpublished September 2025
Checklists Are Better Than Reward Models For Aligning Language Models
AuthorsVijay Viswanathan†, Yanchao Sun, Shuang Ma‡**, Xiang Kong, Meng Cao, Graham Neubig†, Tongshuang Wu†
Checklists Are Better Than Reward Models For Aligning Language Models
AuthorsVijay Viswanathan†, Yanchao Sun, Shuang Ma‡**, Xiang Kong, Meng Cao, Graham Neubig†, Tongshuang Wu†
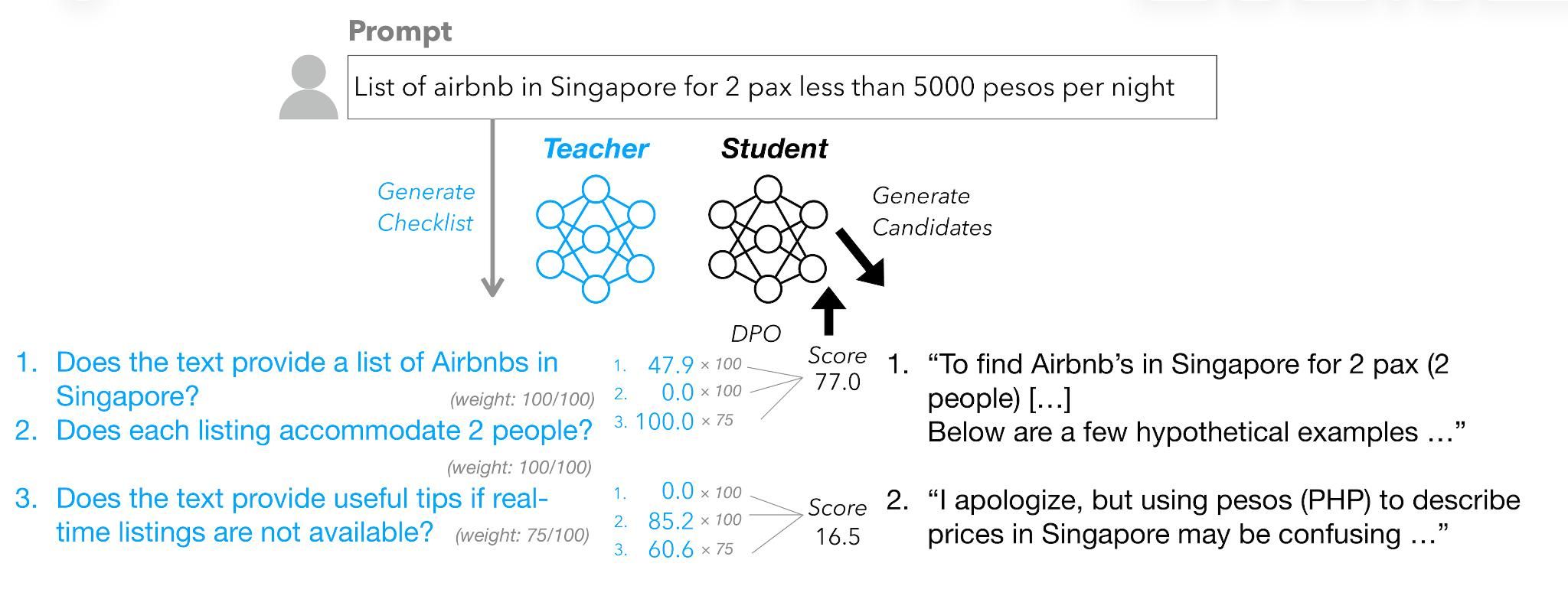
Language models must be adapted to understand and follow user instructions. Reinforcement learning is widely used to facilitate this — typically using fixed criteria such as “helpfulness” and “harmfulness”. In our work, we instead propose using flexible, instruction-specific criteria as a means of broadening the impact that reinforcement learning can have in eliciting instruction following. We propose “Reinforcement Learning from Checklist Feedback” (RLCF). From instructions, we extract checklists and evaluate how well responses satisfy each item - using both AI judges and specialized verifier programs - then combine these scores to compute rewards for RL. We compare RLCF with other alignment methods applied to a strong instruction following model (Qwen2.5-7B-Instruct) on five widely-studied benchmarks — RLCF is the only method to improve performance on every benchmark, including a 4-point boost in hard satisfaction rate on FollowBench, a 6-point increase on InFoBench, and a 3-point rise in win rate on Arena-Hard. These results establish checklist feedback as a key tool for improving language models’ support of queries that express a multitude of needs.
Do LLMs Know Internally When They Follow Instructions?
April 10, 2025research area Speech and Natural Language Processingconference ICLR
Instruction-following is crucial for building AI agents with large language models (LLMs), as these models must adhere strictly to user-provided constraints and guidelines. However, LLMs often fail to follow even simple and clear instructions. To improve instruction-following behavior and prevent undesirable outputs, a deeper understanding of how LLMs’ internal states relate to these outcomes is required. In this work, we investigate whether LLMs…
Do LLMs Estimate Uncertainty Well in Instruction-Following?
April 8, 2025research area Speech and Natural Language Processingconference ICLR
Large language models (LLMs) could be valuable personal AI agents across various domains, provided they can precisely follow user instructions. However, recent studies have shown significant limitations in LLMs’ instruction-following capabilities, raising concerns about their reliability in high-stakes applications. Accurately estimating LLMs’ uncertainty in adhering to instructions is critical to mitigating deployment risks. We present, to our…

Our research in machine learning breaks new ground every day.